前言
Hdfs基本知识
HDFS
数据块
HDFS跨集群存储文件时,会把文件切分成粗粒度的、大小固定的块。默认的HDFS块大小为64MB。hdfs的块比磁盘的块大,其目的是为了最小化寻址开销。数据产品的块大小会影响文件系统操作的性能,如果存储和处理非常大的文件,那么较大的块大小会更高效。数据产品的块大小会影响MapReduce计算的性能,因为Hadoop的默认行为是为输入文件中的每个数据块创建一个map任务。
抽象块的优点
1.文件的大小可以大于网络中任意一个磁盘的容量
2.使用抽象块而非整个文件作为存储单元,大大简化可储存子系统的实现。
namenode 和 datanode
namenode: 管理文件系统的命名空间,维护者文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。
datanode:向namenode报告心跳信息和块列表
namenode上的文件: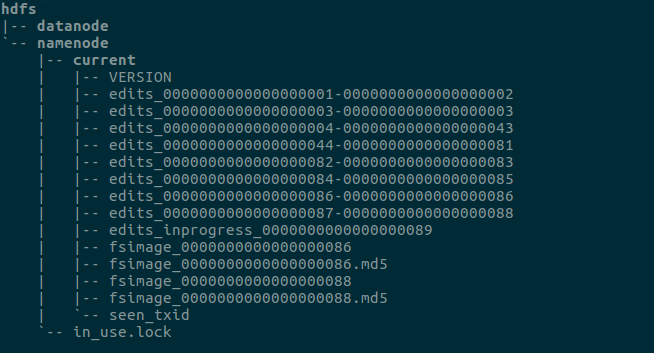
datanode上的文件: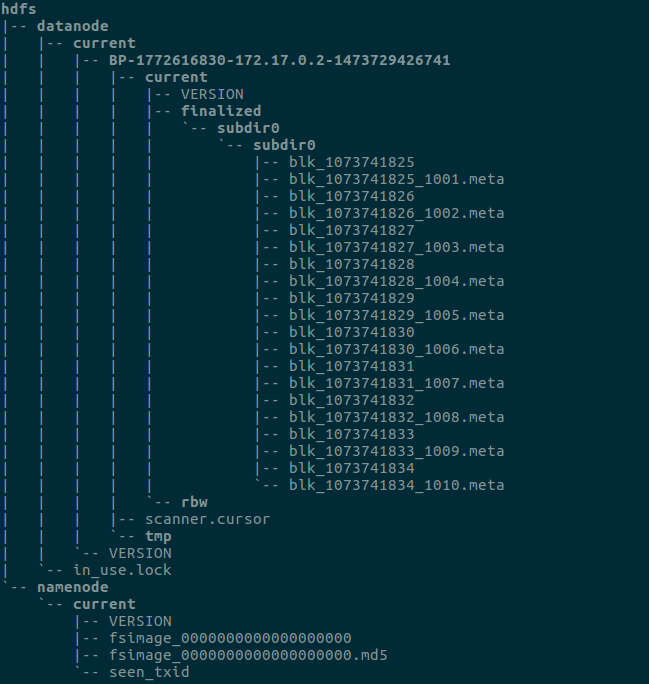
namenode故障:
- 备用namenode快速恢复(通过故障转移控制器监测宿主namenode)
- 管理员申明备用namenode并冷启动
文件系统
基本操作
配置文件系统为hdfs
hdfs://localhost
获取帮助
$ hadoop fs -help
从本地复制文件到hdfs
$ hadoop fs -copyFromLocal input/docs/file /usr/tom/file
复制回去
$ hadoop fs -copyToLocal /usr/tom/file input/docs/file
创建文件夹
$ hadoop fs -mkdir books
查看文件列表
$ hadoop fs -ls
hadoop 文件系统
hadoop 有一个抽象的文件系统概念,HDFS知识其中的一个实现.
java抽象类org.apache.hadoop.fs.FileSystem定义了hadoop的一个文件系统接口,并且该抽象类有几个具体实现
从Hadoop URL中读取数据
使用java.net.URL
123456InputStream in = null;try {in = new URL("hdfs://host/path").openStream();} finally {IOUtils.closeStream(in);}通过URLStreamHandler实例以标准输出方式显示Hadoop 文件系统的文件
123456789101112131415public class URLCat {static {URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());}public static void main(String[] args) throws Exception {InputStream in = null;try {in = new URL(args[0]).openStream();//从in复制数据到System.out, 4096是复制的缓冲区大小, false是复制结束后是否关闭数据流IOUtils.copyBytes(in, System.out, 4096, false);} finally {IOUtils.closeStream();}}}通过FileSystem API读取数据
FileSystem 是一个通用的文件系统API,所以第一步是及按需哦我们需要的文件系统实例,这里是HDFS,获取FileSystem实例有下面这几个静态工厂方法:123public static FileSystem get(Configuration conf) throws IOExceptionpublic static FileSystem get(URL url, Configuration conf) throws IOExceptionpublic static FileSystem get(URL url, Configuration conf, String user) throws IOException
Configuration 对象封装了客户端或服务器的配置,通过设置配置文件读取类路径来实现.
如果需要获取本地文件系统运行实例,可以使用getLocal()
有了FileSystem实例之后,我们调用open()函数来获取文件的输入流
第一个方法使用默认缓冲区大小4KB
重写上面的例子
写入数据
//create()方法会自动创建不存在的父目录
将本地文件复制到Hadoop文件系统
查询文件系统
删除数据
|
|
只有recursive为true时,非空目录及其内容才会被删除, 否则会抛出IOException异常
数据流
客户端读取数据
- 客户端通过调用FileSystem对象的open()方法来打开希望读取的文件。
- DistributedFileSystem通过使用RPC来调用namenode,namenode返回按照离客户端距离排序的datanode地址。DistributedFileSystem返回一个FSDataInputStream对象。
- 客户端对这个输入流调用read()方法,DFSInputStream随即连接最近的datanode。
- 通过对数据流反复调用read()方法,可以将数据从datanode传到客户端。
- 到达块末端时,客户端关闭与该datanode的连接,然后寻找下一个块的最佳datanode。
- 一旦客户端读取完成,就对FSDataInputStream调用close()方法。
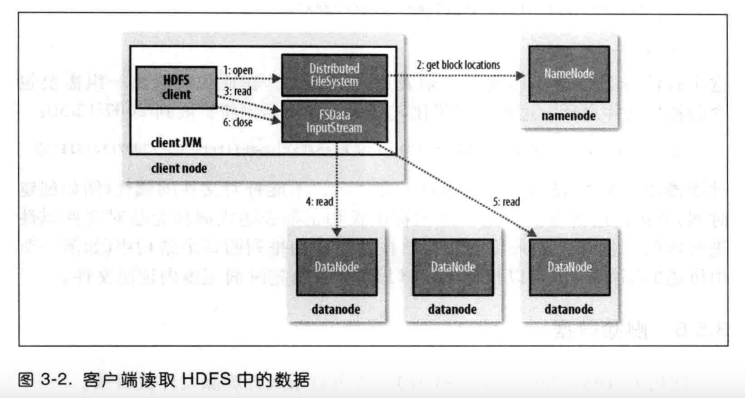
故障处理(1.与datanode通信有问题 2.块损坏):
- 从其他datanode读取数据块的副本。
- 记住有错误的datanode,以后不会再连接这个datanode
- 如果块有损坏,则通知namenode该损坏的块
客户端写入数据
- 客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
- DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时文件还没有相应的数据块。如果文件已经存在或者客户端没有相应权限,就会抛出IO异常。DistributedFileSystem向客户端返回一个FSDataOutputStream对象。
- DFSOutputStream将数据分成一个个的数据包,并写入数据队列。DataStreamer处理队列,根据datanode列表来要求namenode分配适合的新块来存储数据副本。
- 客户端往管道里面写入数据。
- DFSoutputStream维护着一个数据包确认队列。收到管道中所有datanode确认信息后,该数据包才会从确认队列中删除。
- 客户端完成数据的写入后,对数据流调用close()方法。该操作将剩余的所有数据包写入datanode管线,并在联系到namenode发送文件写入完成信号之前,等待确认。
- namenode已经知道文件有哪些块组成(通过Datastreamer请求分配中数据块),所以它在返回成功之前只需等待数据块进行最小量的复制。
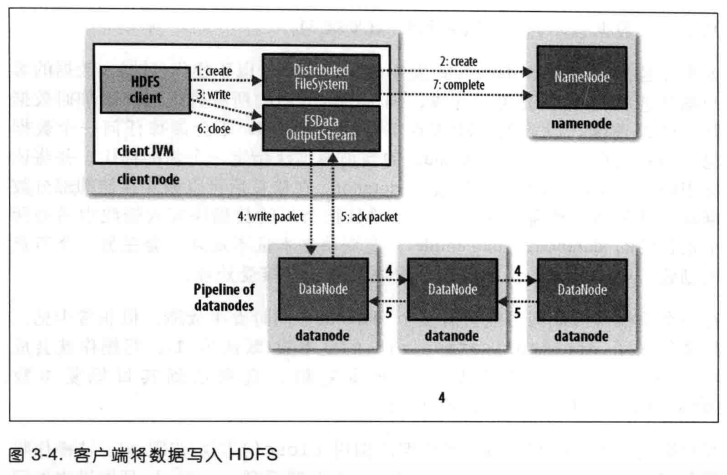
故障处理:
如果写入的时候,复制管道中的某一个DataNode无法将数据写入磁盘(如DataNode死机)。发生这种错误时,管道会立即关闭,已发送的但尚未收到确认的数据包会被退回到队列中,以确保管道中错误节点的下游节点可以得到数据包。而剩下的健康的DataNode中,正在写入的数据块会被分配新的blk_id。这样,当发生故障的数据节点恢复后,冗余的数据块就会因为不属于任何文件而被自动丢弃,由剩余DataNode节点组成的新复制管道会重新开放,写入操作得以继续,写操作将继续直至文件关闭。NameNode如果发现文件的某个数据块正在通过复制管道进行复制,就会异步地创建一个新的复制块,这样,即便HDFS的多个DataNode发生错误,HDFS客户端仍然可以从数据块的副本中恢复数据,前提是满足最少数目要求的数据副本(dfs.replication.min)已经被正确写入(dfs.replication.min配置默认为1)。一致模型
新建一个文件后, 它能在文件系统的命名空间中立即可见.但是,写入文件的内容却不保证立即可见,即使数据流已经刷新并存储.所以文件长度显示为0.当写入的数据超过一个快之后,第一个数据块对新的reader就是可见的.如果其他reader要看到所有已经写入的数据,就应该用hflush()或者hsync()同步方法.
Hadoop 存档
大量小文件会耗尽namenode的内存
har文件,是一个更高效的文档工具,它将文件存入HDFS块,在减少namenode内存的使用的同时,允许对文件进行透明地访问.具体来说,Hadoop存档文件可以用作MapReduce的输入.
使用Hadoop存档工具
|
|