概述
Apache Kafka™ is a distributed streaming platform.
我使用的是 kafka 0.9+。
参考官方文档,本文包括kafka的集群架构和工作原理,配置文件解析,常用脚本命令和java API操作。
kafka的集群架构和原理
Topics and Logs
Topic - 每个消息所属的类别,用来区分消息
partition - 对于一个topic来说,可以配置多个partition来分开存放这个Topic的消息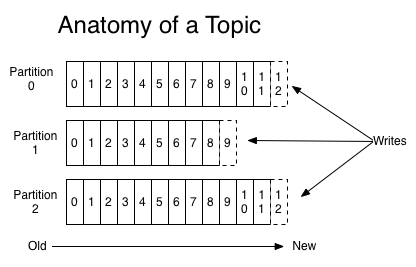
对于一个topic来说,生产出来的消息会被分发到各个partition内存储。一个消息被分发到哪个partition内是可配置的。
消息在每个partition内都是有序的,但是整体是不能保证有序的。partition内的数据存放到日志文件中,每个partition中的记录都被分配一个顺序的id号,称为唯一标识partition内每个记录的偏移量。
kakfa会保留所有的数据,即使是已经被消费过的数据。只有数据过期了才会被删除,数据保留多久是可以配置的。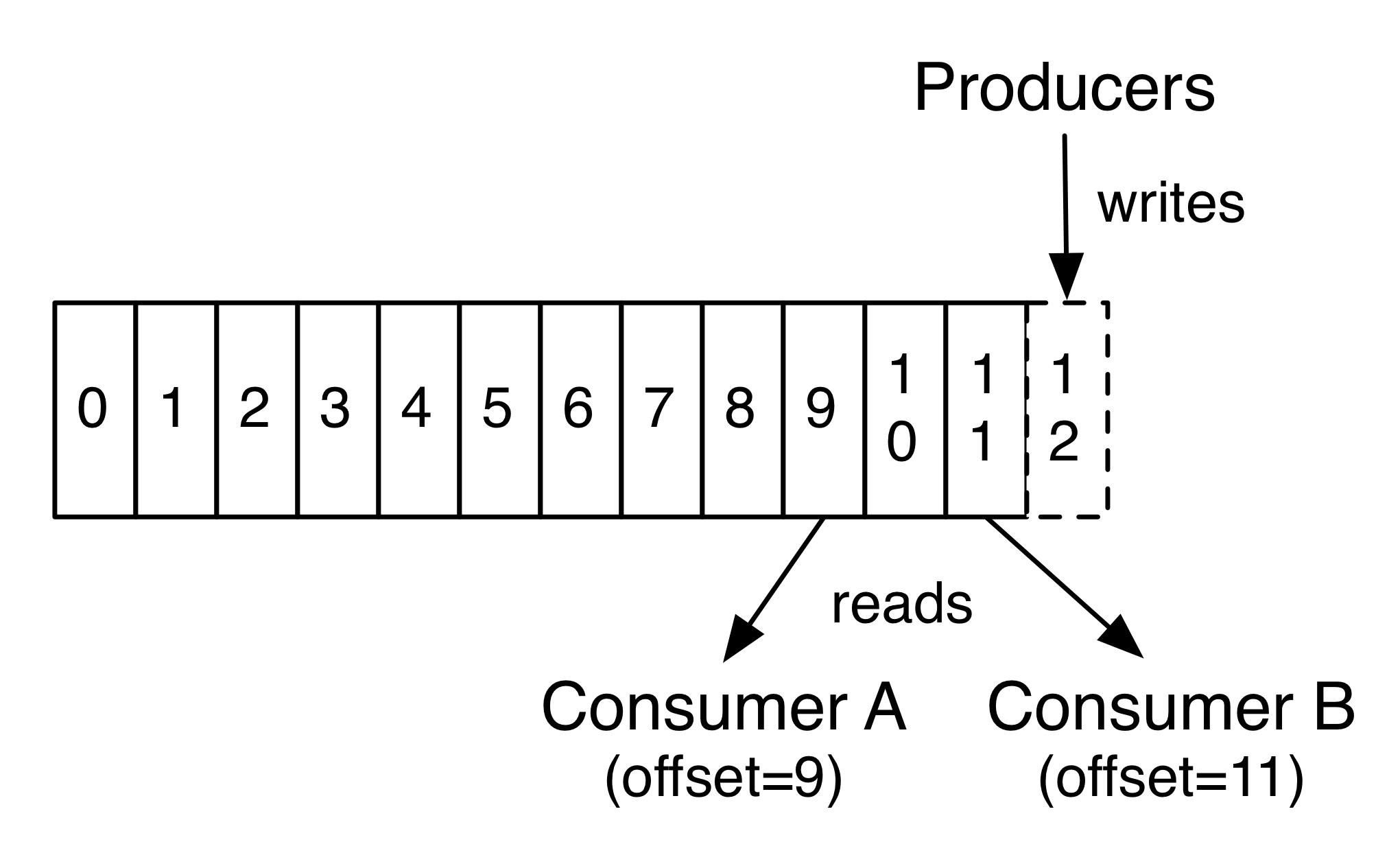
消费者通过partition内的偏移量来读取消息,就像读取一个数组一样,可以重复访问任何数据。
Distribution
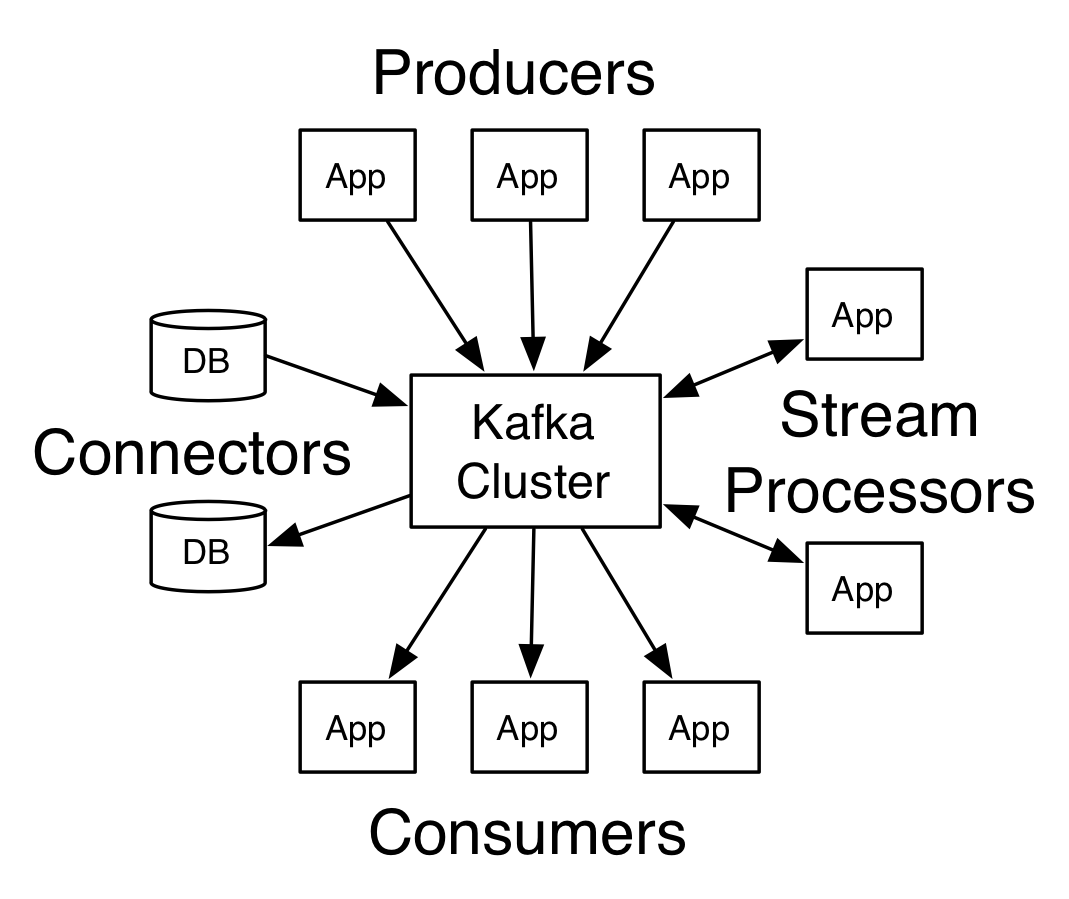
日志的分区分布在Kafka集群中的服务器(broker)上,每个服务器处理数据并请求分区的一部分。每个分区都跨可配置数量的服务器进行复制,以实现容错。
每个分区有一个服务器,充当“leader”,零个或多个服务器充当“关注者”。领导者处理分区的所有读取和写入请求,而追随者被动地复制领导者。如果领导失败,其中一个追随者将自动成为新的领导者。每个服务器都作为一些partitions的leader,和其他的partitions的follower。(既是leader,也是follower)
Producers
生产者将数据发布到他们选择的主题。生产者负责选择要分配给主题中哪个分区的记录。这可以通过循环方式简单地平衡负载,或者可以根据某些语义分区功能(例如基于记录中的某些关键字)来完成。
Consumers
每个consumer都可以指定一个consumergroup,若不指定就属于默认的Group。Consumer Group作为订阅topics的基本单位。该Group订阅的topics中的一个partition只能由组内的一个consumer消费,如果组内的consumers个数多于partitions的数目,那么意味着某些consumers将不会得到任何消息,所以consumer数不能多于partition数。如果某个consumer失败,那么它负责的partitions将会分配到其他的consumer上。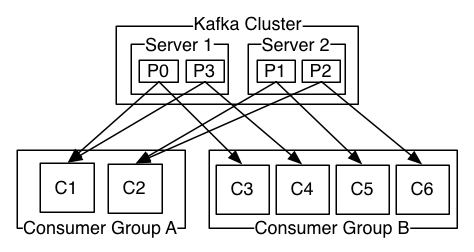
Kafka as a Messaging System
Kafka结合了队列和发布-订阅两种模式。消费者可以顺序读取数据,未来的数据将会发布给订阅者。
Kafka as a Storage System
Kafka的数据都保存在本地磁盘中,每个partion都是一个文件夹(topic-xxx),存放在配置文件中指定的logs.dir中。一个partition由多个segment组成,每个segment由一个索引文件(.index)和一个数据文件(.log)组成。
配置文件解释
server.properties
配置文件
|
|
坑
参考文章
按照官方文档的说法,advertised.host.name和advertised.port这两个参数用于定义集群向Producer和 Consumer广播的节点host和port,如果不定义的话,会默认使用host.name和port的定义。但在实际应用中,我发现如果不定义 advertised.host.name参数,使用Java客户端从远端连接集群时,会发生连接超时,抛出异常:org.apache.kafka.common.errors.TimeoutException: Batch Expired
经过debug发现,连接到集群是成功的,但连接到集群后更新回来的集群meta信息却是错误的.
能够看到,metadata中的Cluster信息,节点的hostname是iZ25wuzqk91Z这样的一串数字,而不是实际的ip地址 10.0.0.100和101。iZ25wuzqk91Z其实是远端主机的hostname,这说明在没有配置advertised.host.name 的情况下,Kafka并没有像官方文档宣称的那样改为广播我们配置的host.name,而是广播了主机配置的hostname。远端的客户端并没有配置 hosts,所以自然是连接不上这个hostname的。要解决这一问题,把host.name和advertised.host.name都配置成绝对 的ip地址就可以了。
producer.properties
|
|
consumer.properties
|
|
常用脚本命令
启用一个broker实例
启用多个broker实例
创建一个topic
删除一个topic
查看所有topic
查看某个topic的详细信息
用控制台生产消息
用控制台消费消息
Use Kafka Connect to import/export data
java API
producer
consumer