摘录自九章官网
前k大的和
初阶:有两个数组A和B,每个数组有k个数,从两个数组中各取一个数加起来可以组成k*k个和,求这些和中的前k大。
进阶:有N个数组,每个数组有k个数,从N个数组中各取一个数加起来可以组成k^N个和,求这些和中的前k大。
答:
初阶:定义C[i][j] = A[i]+B[j],假设A,B从大到小排序,那么C[0][0]为最大的和。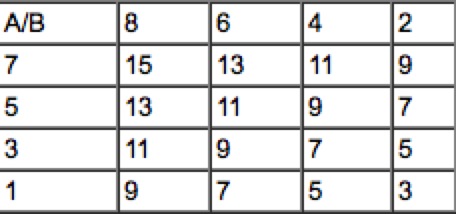
将A和B的和变为一个矩阵,更容易思考
将C[0][0]拿走以后,C[1][0]和C[0][1]则都可能成为第二个最大和。设定可能成为最大和的集合S,一开始S={C[0][0]},每次从集合中选一个最大的数C[i][j]出来,然后将C[i+1][j]和C[i][j+1]加入到集合中(如果有的话)。直到选足k个数。由于同时可能在集合中存在的元素只有n个(每行每列会同时有一个数在集合中),采用堆来实现该集合,每次找一个最大数复杂度O(logn),总时间复杂度O(nlogn)
进阶:先对前两个数组求前k大和,将结果与第三个数组求前k大和,然后第四个……直到第N个。
面试官角度:
初阶问题的难度是需要将所有的和构造成一个矩阵的形式来思考。然后考察基本的数据结构堆的使用。 进阶问题中,考察的是如何将一个复杂的问题化简为一个我们已经知道解法的问题。我们可以解决2个数组求前k大和的问题了,那么N个数组的情况,就想办法变为2个数组的情况就可解了。
分层遍历二叉树
初阶:给一棵二叉树,按照层次进行输出,第一行输出第一层的节点,第二行输出第二层,如此类推。
进阶:如果只给你O(h)的额外空间该怎么办?(h为树的高度)
答:
初阶:采用宽度(广度)优先搜索算法BFS。用一个队列存储一层的节点,通过一层节点扩展出下一层节点。实现的时候有两种方式:一种方式是队列中同时存储层数,发现层数不同了,就换行输出;另一种方式是记录每一层的头尾,多套一层循环输出每一层。时间复杂度O(n),空间复杂度O(n)
进阶:采用迭代搜索。迭代搜索的意思是,设定一个层数限制x,利用深度优先搜索的方式往下搜索,每次搜到x这一层就不再往下继续递归了。通过逐渐放宽x来实现每一层的搜索,也就是x从1到h进行枚举(h为树的高度)。时间复杂度O(nh),空间复杂度O(h)。迭代搜索是常用的在空间不足的情况下替代宽度优先搜索的方法。是一种用时间换取空间的方法。
面试官角度:
考察对于搜索的基础知识熟练程度。深度优先搜索,宽度优先搜索,迭代搜索,是最常见的三种搜索方式。其中初阶问题,还会考察对宽度优先搜索实现的掌握,这是诸多IT公司面试都会考察的内容。
第k大的数
初阶:有两个数组A和B,假设A和B已经有序(从大到小),求A和B中所有数的第k大。
进阶:有N台机器,每台机器上有一个有序大数组,需要求得所有机器上所有数中的第k大。注意,需要考虑N台机器的并行计算能力。
答:
初阶:比较A[k/2]和B[k/2],如果A[k/2]>=B[k/2]那么A的前k/2个数一定都在前k-1大中,将A数组前k/2个数扔掉,反之扔掉B的前k/2个数。将k减小k/2。重复上述操作直到k=1。比较A和B的第一个数即可得到结果。时间复杂度O(logk)
进阶:二分答案S,将S广播给每台机器,每台机器用二分法求得有多少比该数小的数。汇总结果后可判断是该将S往上还是往下调整。
面试官角度:
初阶问题是一个难度比较大的算法题。需要有一定的算法训练功底。主要用到的思想是递归。首先容易想到的方法是合并两个数组(见面试题5,有序数组的合并),这样复杂度为O(k),那么答出这个以后,面试官会问你,还有更好的方法么?这个时候就要往O(logk)的思路去想,O(logk)就意味着需要用一种方法每次将k的规模减小一半,于是想到,每次要扔掉一个数组或两个数组中的k/2个数,于是想到去比较A[k/2]和B[k/2],仔细思考比较结果,然后想到较大的那一方的前k/2个数一定都在前k-1大的数中, 所以可以扔掉。
进阶问题的考察点是逆向思维。二分答案是一种常见的算法思路(见面试题2 抄书问题),所以当你想不出题目的时候,往往可以试试看是否可以二分答案。因为需要发挥N台机器的并行计算能力,所以想到让每台机器互不相关的做一件事情,然后将结果汇总来判断。
一般来讲,面试中问题这两个题目,说明职位对算法能力的要求还是比较高的。
赛马问题

随机数生成器
有一个随机数生成器,每次等概率的返回1到5中的一个整数。现在需要你利用这个随机数生成器来设计一个新的随机数生成器,每次可以等概率的返回1到7中的一个整数。
答:
随机两次rand(5)相当于随机一次rand(25),将前21个数三三一组分为7组,如果得到的数<=21,则返回对应组号; 如果>21则重复上述过程,直到得到的数<=21。
时间复杂度为O(221/25 + 4 21/25 4/25 + 6 21/25 4/25 4/25 … ) = O(1)
面试官角度:
这个题目的解题思路有一点智力题的感觉。因为5和7互质,所以无法找到5^n被7整出。一个基本的陷阱是,调用两次rand(5)得到的是rand(25)而不是rand(10)。
递增矩阵
递增矩阵是指每一行和每一列均从小到大排列矩阵。给你一个递增矩阵A和整数x,设计一个算法在A中查找x,找不到返回无解。
答:
从矩阵的右上角出发(左下角同理),如果该数
面试官视角:
如果是一个有序的数组中找一个数,那么自然是用O(logn)的二分法。升级为有序矩阵之后,自然也容易想到二分法。但进一步想会发现,如果从矩阵中间选择一个数,每次只能去掉1/4,而且破坏了矩阵的形状,无法进行递归。因此二分的思路就变得不可行了。从而将复杂度提高一点想一想O(n)的方法,思路上仍然是根据与x比较大小来决定扔掉一些数,于是中间不行,就尝试4个角,从而发现可以从右上角出发来进行查找。
最大子区间/矩阵
初阶:数组A中有N个数,需要找到A的最大子区间,使得区间内的数和最大。即找到0<=i<=j<N,使得A[i]+A[i+1] … + A[j]最大。A中元素有正有负。
进阶:矩阵A中有N*N个数,需要找到A的最大的子矩阵。
答:
初阶:设Sum[i] = 前i个数的和,Min[i] = min{Sum[1], Sum[2] … Sum[i-1]}。从左到右枚举i,计算Sum[i]-Min[i]的最大值,即为答案。时间复杂度O(n),空间复杂度O(1),只需要在枚举的过程中记录一个Sum,一个Min和一个全局答案的Max即可。
进阶:枚举最大子矩阵的上下边界x和y,将第x行到第y行每一列的数叠加成为一个数。然后就成为了一个初阶的问题。时间复杂度O(n^3)。
面试官角度:
初阶问题有若干种解法,上面给出的是枚举的方法。一种贪心的方法是,累加Sum的过程中,如果Sum<0,就让Sum=0(意味着之前的数不如不取,所以全部扔掉)。进阶的问题主要是考察是否能将其简化为初阶的问题来解决。其中进阶问题一般会考察程序实现,需要进行练习。
超过一半的数
初阶:有N个数,其中一个数的出现次数严格超过了一半。求这个数。
进阶1:有N个数,其中两个数的出现次数都超过了⅓ ,求这两个数。
进阶2:有N个数,其中一个数的出现次数严格超过了⅓,并且没有第二个这样的数。求这个数。
以上两问均要求O(n)的时间复杂度和O(1)的额外空间复杂度。
答:
初阶:抵消法。如果两个数不一样,扔掉这两个数,剩下来的数中,要找的数的出现次数仍然会超过一半。所以整个过程中只需要保存一个数,及其出现次数即可。
进阶1:仍然是抵消法。如果三个数不一样,就三个数都扔掉。因此记录2个数,及其各自出现次数即可。
进阶2:沿用进阶1的算法。如果最后剩下1个数,那么就是答案了;如果剩下2个数,重新扫描这N个数,统计这两个数的出现次数则可以得到答案。
面试官视角:
初阶问题是著名的芯片测试问题的另一个版本。一般来讲大学的算法课上都会讲到。主要考察的是算法基本功底。进阶1和进阶2都是需要想办法利用初阶问题的思路去解决,如果只是背下了初阶问题的解答没有真正理解,进阶问题就无法回答出来。进阶2在回答的时候需要和面试官沟通是否可以再扫描一遍数组。
字符串编辑距离
有两个字符串A和B,对A可以进行如下的操作:插入一个字符,删除一个字符,替换一个字符。问A可以通过最少多少次操作变为B?我们定义这个结果为字符串的最小编辑距离。
答:
动态规划。设f[i][j]代表A的i个字符与B的前j个字符完美匹配上时,需要的最小操作次数。有状态转移方程如下:
f[i][j] = min{f[i-1][j] + 1, f[i][j-1] + 1, f[i-1][j-1] + 1} // if A[i] != B[j]
= min{f[i-1][j] + 1, f[i][j-1] + 1, f[i-1][j-1]} // if A[i] == B[j]
答案为f[A.length][B.length]。时间复杂度O(n^2)。
面试官角度:
字符串编辑距离是经典的动态规划问题,一般来说,这个题目还会要求实现。读者可以尝试自己写写看。写动态规划时需要注意的地方有:初始化,循环边界。一个类似思路的题目有:最长公共子序列。
01随机生成函数
有一个01随机生成函数,rand(2),以p的概率生成1,1-p的概率生成0。请用这个生成函数设计一个等概率的01随机生成函数。
答:
随机2次,可能的结果有,00, 01, 10, 11。概率分别为:(1-p)(1-p), (1-p)p, p(1-p), pp。可以发现01和10的生成概率是相等的。因此让01代表0,10代表1,如果随机出了00或者11,就再随机2次。
面试官视角:
本题和九章算法面试题13都是经典的随机数生成函数的题目。他们用到的一个基本思路通过多次随机构造答案所需要的等概率事件,该事件可能是生成结果的一个子集,在子集以外的结果,就重新来一次。
从输入流中随机取记录
有一个很大很大的输入流,大到没有存储器可以将其存储下来,而且只输入一次,如何从这个输入流中等概率随机取得m个记录。
答:
开辟一块容纳m个记录的内存区域,对于数据流的第n个记录,以m/n的概率将其留下(前m个先存入内存中,从第m+1个开始),随机替换m个已存在的记录中的一个,这样可以保证每个记录的最终被选取的概率都是相等的。
面试官视角:
这个题目除了需要给出正确解答以外,还需要证明你的解答。考察的是对概率随机问题的掌握情况和归纳法的运用。下面给出一个简单的证明:
设数据流中已经有n个记录流过,在内存中的m个记录中,假设都是等概率取得的,每个数命中的概率都为:mn。对于第n+1个记录,以mn+1的概率选中,如果没有选中,则内存中的m个记录均被留下来,每个数留下来其概率为:mn (1-mn+1) = m(n+1-m)n(n+1);如果选中,新留下来的数概率自然是mn+1,而原来内存中的m个数中留下来m-1个数,每个数留下来的概率是:mnmn+1*m-1m = m(m-1)n(n+1)。两种情况下概率之和为m(m-1)n(n+1)+m(n+1-m)n(n+1)=mn+1,即为原来被选中数,继续被选中的概率。由此我们不难得出,内存中每个数被选中概率一直都是mn。
复制链表
初阶:复制一个简单链表。假设链表节点只包含data和next。
进阶:假设链表节点新增一个属性叫random,他随机指向了链表中的任何一个节点。复制这个链表。
答:
初阶:编程实现(略)。
进阶:将1->2->3->4->NULL先复制为1->1->2->2->3->3->4->4->NULL,然后再拆开。
面试官角度:
链表复制是考察对指针运用的熟练程度。对于初阶和进阶的问题都会要求实现。关键点并不在于想出进阶问题怎么做,而是一定要把实现写好。对于进阶问题的做法如何想到,就看你聪不聪明或者是不是准备过这个题目了。
最常访问IP
给你一个海量的日志数据,提取出某日访问网站次数最多的IP地址。
答:
将日志文件划分成适度大小的M份存放到处理节点。
每个map节点所完成的工作:统计访问百度的ip的出现频度(比较像统计词频,使用字典树),并完成相同ip的合并(combine)。
map节点将其计算的中间结果partition到R个区域,并告知master存储位置,所有map节点工作完成之后,reduce节点首先读入数据,然后以中间结果的key排序,对于相同key的中间结果调用用户的reduce函数,输出。
扫描reduce节点输出的R个文件一遍,可获得访问网站度次数最多的ip。
面试官角度:
该问题是经典的Map-Reduce问题。一般除了问最常访问,还可能会问最常访问的K个IP。一般来说,遇到这个问题要先回答Map-Reduce的解法。因为这是最常见的解法也是一般面试官的考点。如果面试官水平高一点,要进一步问你有没有其他解法的话,该问题有很多概率算法。能够在极少的空间复杂度内,扫描一遍log即可得到Top k Frequent Items(在一定的概率内)。有兴趣的读者,可以搜搜“Sticky Sampling”,”Lossy Counting”这两个算法。
寻找重复的URL
给定A、B两个大文件,各存放50亿个url,每个url各占256字节,内存限制是4G,让你找出同时在A和B中出现的url。
答:
方法1:使用BloomFilter(一种类似于hash表但比hash表占用空间更小的查重数据结构),通过K个不同的hash函数,将5G个URL映射到32G个bit位上,当且仅当K个hash函数得到的bit位上都是1时,代表该url重复出现。一般来讲K取8。该方法存在精度损失。时间复杂度O(n)。
方法2:用一个hash函数将A的5G个url分散到5*256/4=320个文件中(A0,A1..),相同文件的url的hash值%320相等。这样每个文件平均为4G大小。对B做同样处理(B0,B1…)。然后顺序处理Ai与Bi即可,此时只需要使用简单的hash表将url全部倒入内存。这种方法比方法1得到的答案更精确,但同时速度也更慢,因为方法1只有10G次读操作,方法2需要20G次读与10G次写(如果都不算答案输出的写操作的话)。
面试官角度:
小内存中大文件处理的解答方法主要有如下几个角度:
- 考虑精确结果和不精确结果采用不同的算法
- 尽量减少文件写操作
- 使用BloomFilter
- 使用MapReduce
尝试这4个角度去解答,总不会错。对于这类问题,时间复杂度已经不是主要考点了。
寻找最近单词对
初阶:有一篇包含N个单词的文章和M个单词对,对于每个单词对,如果他们在文章中都出现了,求出他们在文章中的最近距离。例如文章为:ABBCABC,那么对于单词对(A,C)的最近距离是1(最后的ABC,A必须在C的前面)
进阶:假设N和M都是海量数据,有什么好的方法可以优化?
答:
初阶:扫描文章的单词序列,对于单词对(W1,W2)记录最后一次出现W1的位置P1,当扫描到W2时,计算当前位置和P1的距离,保存下最优的方案。
进阶:使用Map-Reduce对各个单词及其位置建立索引。对于一次请求中的单词对(W1,W2)在索引中获得位置列表,遍历两个列表得到结果。如果两个列表的长度相差不大,则线性扫描,如果相差很大,则使用二分法查找。
面试官角度:
本题的初阶考察点是编程实现。进阶问题考察点主要是“索引“ ”MapReduce“和在两个数组中招最近元素时,根据数组的长度差距来选择使用线性扫描还是二分查找。
#二分#
#二分查找#
#二分法#
#大数据#
#MapReduce#
扔棋子
初阶:有一个100层高的大厦,你手中有两个相同的玻璃围棋子。从这个大厦的某一层及更高的层扔下围棋子就会碎,用你手中的这两个玻璃围棋子,找出一个最优的策略(扔最少的次数),来得知那个临界层面。
进阶:如果大厦高度是N层,你有K个棋子,请问最少需要扔几次可以知道得临界层?
答:
初阶:推导过程如下:首先在第x层仍一个玻璃围棋子,如果碎了,则利用另一个玻璃围棋子依次从1~x-1层试探,查找临界层;如果第x层未碎,则在第x+(x-1)=2x-1层仍一个玻璃围棋子,如果碎了,则利用另一个玻璃围棋子一次从x+1~2x-2层查找临界层,…,这样,可得到表达式:x+x-1+…+1>=100,可得到x=14,即:
先从14层扔(碎了试1-13)
再从27层扔(碎了试15-26)
再从39层扔(碎了试28-38)
再从50层扔(碎了试40-49)
再从60层扔(碎了试51-59)
再从69层扔(碎了试61-68)
再从77层扔(碎了试70-76)
再从84层扔(碎了试78-83)
再从90层扔(碎了试85-89)
再从95层扔(碎了试91-94)
再从99层扔(碎了试96-98)
最后从100层扔(根据题意一定会碎,也可以不扔了)
最坏情况下扔14次。
进阶:
动态规划。设F[N][K]为N层楼,K个棋子最少仍几次。有状态转移方程如下:
F[N][K] = min{max(F[i][K-1]), F[N-i][K])+1, 1<=i<=N}
初始状态下,F[i][1] = i-1 // 如果只有一颗棋子,最坏情况下要从第1层一直扔到第i-1层才能确定(因为第i层一定会碎,不用扔)
时间复杂度O(N^2 * K)
栈上实现Min函数
实现一个带Min函数的栈(Stack),让其可以支持O(1)的Push,O(1)的Pop,O(1)的Top和O(1)的Min(返回整个Stack中的最小元素)。
答:
用两个Stack,其中Stack1保存原始数据。Stack2保存最小值更新序列。如对于数据4 5 3 1 2(最后边是栈顶),Stack1的数据为[4,5,3,1,2],Stack2的数据为[4,3,1],Stack2的Top()一直保存的是Stack1中的最小元素。
Min(): 返回Stack2.Top()
Push(x):首先在Stack1中Push(x),然后比较Stack2的Top与x的大小,如果x更小则Push到Stack2中
Top(): 返回Stack1.Top()
Pop(): 从Stack1中Pop()出栈顶元素,与这个Stack2的Top()进行比较,如果相同,则Stack2中也Pop()出栈顶元素。对于处理存在相同数值元素的问题,可以在Stack2的每个数加一个计数器,计数器减到0则Pop()
面试官角度:
说实话这个题目纯粹就是看过就知道,没看过除非你搞过竞赛或者真的特别聪明才可能想得出来。关键点是用两个Stack来实现。对于这种问题大家不必纠结,记住这个题就行了。如果问到你这个题然后你又正好没看过也想不出来,那只能说你看的题目还不够多。
#栈# #Stack#
Fizz Buzz
初阶:给一个区间[a,b],对于区间中每个数,如果是3的倍数,输出Fizz,如果是5的倍数,输出Buzz,如何能同时是3和5的倍数,输出FizzBuzz。
进阶:假如有很多个除数和对应的单词被放在一个Hash表中(上述例子为{3: “Fizz”, 5:”Buzz”})。请问有什么方法可以加快运算效率?
答:
初阶:for区间中的每个数,先判断能否被15整除,然后判断被3整除,然后判断被5整除。注意跳过0。
进阶:时间最优的方法-开一个区间那么大的数组,数组的每个元素是一个字符串,对于每个除数,枚举他在区间中的所有倍数,然后将单词加入数组中对应位置。时间复杂度O(n),n为答案的个数。空间复杂度O(b-a)
空间最优的方法-上述方法需要开辟一个大数组,在区间很大,而除数不多的情况下并不划算。对于每个除数,计算出每个除数的第一个大于等于左区间的倍数,然后放入一个堆。每次从堆中取出一个数,讲结果记录,并讲该结果加上对应除数,放回堆。时间复杂度O(nlogm),m为除数个数。空间复杂度O(m)。
面试官角度:
不要小看初阶问题。初阶问题可以难倒99.5%的面试者。这个问题是著名的面试问题之一。他的考点主要在于编程实现和细节处理。如需要考虑区间a,b中是否包含了0,因为0不算倍数。然后需要先判断是否整除15而不是先判断是否整除3(思维惯性)。
进阶问题主要考察的是是否做过筛数法(一种求质数的方法)和是否对堆有一定了解。思路是:假如而除数很大,那么有很多数实际上是不会被任何除数整除的,但这些数有都需要尝试去除以每个除数,这样耗费就很大。所以采用“逆向思维”,尝试去构造出整个答案序列,而不是每个每一个可能的答案再判断是不是答案。既然构造的话,就想到,对于每个除数,实际上他代表了一个数列:[3, 6, 9, 12 …] 和 [5, 10, 15, 20 …] 你要做的工作实际上是合并两个有序序列。除数有m个的话,就是合并m个有序序列,这个自然就想到了多路归并算法,用堆来实现。
#堆#
#多路归并#
#筛数法#
#基础题#
反转单词序列
将一个句子中的单词逆序排列。要求使用O(1)的额外存储空间。如I Love You逆序之后是You Love I
答:
定义操作Reverse(start, end),该操作可以使用O(1)的额外空间将start-end这段字符逆序。那么方法是,先将整个字符串反转,然后再遍历每个单词,将每个单词单独反转。
面试观角度:
这个题目可能你还会想到其他的解法。但是这个解法是面试官想要的。这个题目还会要求实现。O(1)的空间复杂度内实现Reverse的方法是通过一前一后两根指针,不停地交换字符直到指针相遇。
#两根指针#
方格取数
初阶:有一个n*m的矩阵,需要从坐上角(1,1)走到右下角(n,m),只能向右和向下走。矩阵中的每个方格有一个非负整数,问从左上角到右下角的所有路径中,数字之和最大的路径是哪一条。
进阶:如果可以从左上角往下走k次,每个方格中的数被取走之后第二次经过则不再累加数值。请问走k次最多能取到的数值之和是多少。
答:
初阶:采用动态规划算法。F[i][j]代表从左上角到(i,j)这个位置的最大路径和。有F[i][j] = max{F[i-1][j], F[i][j-1]} + A[i][j]。其中A[i][j]为(i,j)这个格子中的数值。答案为F[n][m]。时间复杂度O(n*m)。
进阶:采用网络流算法。将每个格子拆为两个点——入点和出点,入点到出点之间的流量限制为1,费用为格子的数值。所有出点均向它右方和下方的入点连一条流量限制为无穷大,费用为0的边。连接源点到左上角入点,流量设为k,费用设为0。设右下角的出点为汇点。从源点到汇点做一次最小费用最大流算法,即可得到答案。
面试官角度:
初阶问题是经常会被问到的问题。也是必须要掌握的动态规划算法问题之一。类似的题目有数字三角形。进阶问题一般不会被问到,在北美的面试中基本没有被问到过。再国内的面试中,有一些公司很牛但招聘名额很少时会问到这个题目,笔者曾经在参加面试时被问到的这个题。一般来说网络流算法不会在面试中被问到,所以读者不用担心也不必准备此类问题。只需要掌握初阶问题这种最基本的动态规划算法即可。
#动态规划#
#网络流#
最大连续子集
给一个整数集合S,定义S的子集D为连续子集当且仅当D中的整数构成连续的整数序列。求S的最大连续子集,即包含连续整数最多的子集。如{1, 3, 4, 100, 200, 2}的最大连续子集为{1,2,3,4}
答:
下面给出一个时空复杂度都是O(n)的方法:使用Hash表,索引当前找到的所有连续子集。对于每个集合,索引{第一个数: 集合}和{最后一个数: 集合},如:{1: {1, 2, 3}, 3: {1, 2, 3}, 5: {5, 6}, 6: {5, 6}} 。遍历S的时候,假设遍历到数k,检查k-1为最后一个数和k+1为第一个数的集合在Hash表中是否存在,如果存在则和k一起合并为一个大的集合,删除之前的集合,并加入新的集合。这样每一次操作时间复杂度是O(1)的。最后找到Hash表中最大的集合输出即可。
面试官角度:
这个题目的考点是Hash表。首先你可以答一个简单的排序的方法,复杂度是O(nlogn),这时候面试官会提示是否有更好的方法,于是要去想O(n)的方法。那么自然也就是需要考虑到S集合只能遍历一次。考虑使用一些O(1)复杂度的数据结构来加速运算,则想到Hash表。进而想到对于已经找到的集合,在Hash表中存储左右边界。
#Hash表#
#Hash#
#哈希表#
链表找环
初阶:给一个单链表,判断这个单链表是否存在环,如1->2->3->4->2是一个存在环的链表。要求使用O(1)的额外空间。
进阶:求出环的入口。同样要求O(1)的额外空间。
答:
初阶:用两根指针,从链表头出发,一根慢指针每次走一步,另外一根快指针每次走两步。直到他们相遇(有环)或者快指针走到NULL(无环)。
进阶:相遇之后,将一根指针挪到链表头,两根指针每次都移动一步,直到再次相遇,相遇点即为环入口。
面试官角度:
快慢指针的问题并不常见,用到这个思路的问题除了链表找环以外,还有链表找中点(要求一次扫描)。这个问题属于考烂的问题,也属于我知道就知道,不知道就拉倒的问题。大家记住这个问题的答案即可。具体的分析,读者可以自行在纸上演算。
#链表#
#linked list#
#指针#
子矩阵的最大公约数
给定n*n的矩阵,需要查询任意子矩阵中所有数字的最大公约数。请给出一种设计思路,对矩阵进行预处理,加速查询。额外的空间复杂度要求O(n^2)以内。
答:
构建二维线段树。预处理时间O(n^2),每次查询O(log n)
面试官角度:
这个题目需要具备一定的数据结构功底。线段树(Interval Tree)可以解决的问题是那些满足结合律的运算。最大公约数是一个满足结合律的运算。所以有,GCD(A,B,C,D) = GCD(GCD(A,B), GCD(C, D)) 。同样具备结合律的运算有PI,SUM,XOR(积,和,异或)。线段树的基本思想是,将区间[1,n]查分为[1, n/2], [n/2+1,n]这两个子区间,然后每个子区间继续做二分,直到区间长度为1。在每个区间上维护这个区间的运算结果(如GCD,SUM),需要查询某一段区间的结果时,将该区间映射到线段树上的若干不相交的区间,将这些区间的结果合并起来则得到了答案。可以证明任何一个区间可以映射到线段树上不超过O(log n)个区间。上面介绍的是一维的线段树,对于二维的情况,可以采用四分或者横纵剖分的方法来构建线段树。
#线段树#
#矩阵#
最短距离和
初阶:在一个n*m的矩阵中,有k个点,求矩阵中距离这k个点的距离和最近的点。
进阶:如果要求这个点与所给的k个点不重合,该怎么办?
注:这里的距离采用曼哈顿距离——|x0-x1| + |y0-y1|
答:
初阶:因为采用曼哈顿距离,所以可以分开考虑x坐标和y坐标。将k个点的x坐标排序,可以知道要求的x坐标一定在这k个点的x坐标上,扫描一遍并统计到各个点的x坐标距离和,找到使得距离和最小的x坐标。这一步只需要O(k)的时间复杂度,而不是O(k^2),怎么优化这里不多赘述。对y坐标做同样的操作,从而得到答案。时间复杂度O(klogk),排序的复杂度。
进阶:通过初阶的算法得到一个最优位置,如果这个位置与k个点重合,则从这个位置开始进行搜索,将这个点周围的点和对应的距离放入到一个堆里,每次从堆中取出最小距离的点,然后将这个点周围的点放入堆中,直到取出的点不与所给k个点重合。时间复杂度klogk,因为最多从堆中取出k+1个点即可找到一个不与所给k个点重合的点。堆每次操作为logk。
面试官角度:
本题的最优算法较难想到。所以如果公司要求不高,答出O(nm)的方法即可。O(nm)的方法是因为假设我们知道在(x,y)这个位置的距离和为S,那么当(x,y)移动到(x+1,y)和(x,y+1)的时候,我们可以在O(1)的时间更新S。方法是预处理每一行上方/下方有多少个k个点中的点,每一列左侧/右侧有多少个k个点中的点。上面的解答基于nm>>klogk,如果k比较大,则还是O(nm)的方法更好。答题时需要答出对于给定参数不同情况下采用不用算法这一点。
#堆#
#矩阵#
#排序#
子数组的最大差
给定一个数组,求两个不相交的并且是连续的子数组A和B(位置连续),满足|sum(A) - sum(B)|最大(和之差的绝对值)。例如[2, -1, -2, 1, -4, 2, 8],可以得到A=[-1, -2, 1, -4], B=[2, 8],最大差为16。
答:
预处理每个位置往左/右的最大/最小子数组,然后再枚举划分位置,求得所有MaxLeft[i] - MinRight[i+1]和MaxRight[i+1] - MinLeft[i]中的最大值,即为答案。预处理O(n),枚举划分位置O(n),整体O(n)。
面试官角度:
在《九章算法面试题12 最大子区间/子矩阵》中,我们介绍了在O(n)时间内求得最大子数组(子区间)的方法,在这个题目中,实际上是通过枚举划分位置(AB两个数组中间的间隔)来将求两个数组之差最大的问题变为了求某个数组最大/最小子数组的问题。最小子数组只需要将每个数取相反数则可用最大子数组的方法来求得。
仔细考虑本题,实际上A数组和B数组一定是相邻数组,因为假设A和B之间存在一段数字,假设和为C,如果C>0则可以加入A和B中较大的一边让差变得更大,如果C<0,则加入较小的一边也可以让差变得更大,如果C=0,加入A或者B都不会影响结果。因此,只需要计算每个位置开始往左取到的最大/最小小连续和与往右取到的最大/最小连续和,即可得到答案。
小球排序
有红黄蓝三色的小球若干排成一列,这些小球进行排序,请使用尽量少的空间和时间。
答:
假设顺序为红色黄色蓝色。用两根指针从头开始遍历,第一根指针遇到非红色时停下,如果第二根指针找到第一根指针之后的第一个红色停下,交换两根指针所指颜色。重复上述过程。直到第二根指针找不到任何红色。此时第一根指针到最后都是黄色或蓝色。以黄色为标准继续往后做相同的操作,则可以把黄色和蓝色排好序。在遍历的过程中,由于第二根指针不需要每次都回到第一根指针所在位置往后遍历,所以复杂度是O(n)的。
面试官角度:
这个题目是对排序算法的考察。很显然,一般来说求职者至少都能够答上O(nlogn)的排序方法。进一步也可能会想到使用计数排序的O(n)的方法(因为只有三个颜色,统计每个颜色的个数即可)。此时面试官会要求说,如果不适用计数排序,通过简单的比较和交换能否获得O(n)的效率呢?很多求职者此时就会蒙掉,因为他们觉得计数排序已经最好了,面试官一定是在为难自己。在面试的过程中如果出现这种心态(觉得面试官为难自己)是非常可怕的,面试官从来不会为难求职者。面试官只是希望通过设定不同的限制条件,考察求职者的思维活跃程度。因为在实际工程中,很多情况下,都无法完全在理想的外界环境下考虑问题,需要同时考虑很多限制条件,此时正是你展现才能的时候,抓住面试官“为难”你的机会,才能脱引而出,拿到Offer。
关键词
#排序#
数组波峰
一个数组A[1..n],假设数组中没有任何相邻两数相等,满足A[1]
答:
根据条件A[1]
面试官角度:
这个考察的是二分法。从思考的角度来讲,首先面试者要分析出,题目中所给的几个条件所以代表的意义(A中一定存在波峰),然后通过二分法逐渐缩小可能存在解的区间。答出二分法的解法以后,进一步会问,如果A中的相邻两数可能相等,该怎么做?此时面试者需要从头梳理条件,分析出,A中已经不一定存在波峰了,每次二分以后,也难以每次确定哪边会有波峰。因此,如果相邻两数可能相等,则需要O(n)的算法复杂度来找到A中的波峰。
#二分法#
#数组#
最长01子串
有一个仅有0和1组成的01串,找到其中最长的一段子串,使得该子串中0和1的数目相等
答:
如果将0看做-1,则我们要找的子串是最长的和为0的子串。这种子串求和的问题,一般采用前缀和的方法来解决。用Sum[i]代表前i个数的和,问题的模型转换为,找到i和j,满足Sum[i] 与Sum[j]相等,且|i-j|最大。使用Hash表作为辅助数据结构,Hash表中记录了获得某个Sum时最小的i。从左到右遍历Sum[i],在Hash表中查找是否存在,如果存在,则记录下Hash[Sum[i]] 和i的距离差,否则Hash[Sum[i]] = i。一次遍历结束后得到最大的距离差,同时也可以得到具体是哪一段。
面试官角度:
类似的题目还有“和最大的子数组”, “和为0的子数组”,“和最接近0的子数组”。其通用的解决方法都是通过前缀和Sum[i]来解决。
构造最大数
给定一个只包含正整数的数组,给出一个方法,将数组中的数拼接起来,使得拼接后的数最大。例如,[1, 32, 212]拼接之后,所得到的最大数为322121。
答:
将所有数按照如下规则排序:order(A) < order(B) 当前仅当AB>BA。如31和234,31234 > 23431,所以31应该在234的前面。排序之后将所有数拼接在一起即是答案。
面试官角度:
这是一道贪心算法题,一般来说,都会想到要把第一个数字大的数放前面(总位数固定,自然高位数字越大越好),那么如何将这种你可能能用几句话描述出大概意思的规则变为让程序可以实现的规则,是这个问题的考点。通常求职者都可以答出大致的规则,但是具体落实到程序上,就不尽然都能完美实现。
#贪心#
#数组#
交错的字符串
给定三个字符串A, B, C,判断C是否由A和B交错构成。交错构成的意思是,对于字符串C,可以将其每个字符标记为A类或B类,使得我A类的每个字符顺序构成了A字符串,B类的每个字符顺序构成了B字符串。如:对于A=”rabbit” B=”mq”, ”rabmbitq”是由A和B交错构成的,但”rabbqbitm”不是由A和B交错构成。
答:
采用动态规划算法。令f[i][j]代表A中取前i个字符,B中取前j个字符,是否和C中的前i+j个字符交错匹配。推导出状态转移方程:
f[i][j] = f[i-1][j] && A[i-1] == C[i+j-1] || f[i][j-1] && B[j-1] == C[i+j-1]
初始化:f[0][i] = B.prefix(i) == C.prefix(i); f[i][0] = A.prefix(i) == C.prefix(i);
时间和空间复杂度均为O(n^2)
面试官角度:
两个序列(or 字符串)的动态规划是常见的动态规划面试题,最典型的例子如LCS问题(最长公共子序列)和Edit Distance(字符串编辑距离)。其状态的表示方法是类似的,均为f[i][j]代表A串的前i个字符和B串的前j个字符”匹配”起来的情况。如果理解了LCS这类问题,那么本题本质上只是做了一些简单的变换,思路上几乎是一模一样的。
#字符串#
#动态规划#
#string#
#dp#
#dynamic programming#
主元素
主元素(Majority Number)定义为数组中出现次数严格超过一半的数。找到这个数。要求使用O(1)的额外空间和O(n)的时间。
进阶1:如果数组中存在且只存在一个出现次数严格超过1/3的数,找到这个数。要求使用O(1)的额外空间和O(n)的时间。
进阶2:如果数组中存在且只存在一个出现次数严格超过1/k的数,找到这个数。要求使用O(k)的额外空间和O(n)的时间。
答:
采用抵消法。一旦发现数组中存在两个不同的数,就都删除,直到剩下的数都一样。此时剩下的数就是主元素。因为每次抵消操作之后,剩下来的数种,主元素一定也还是超过一半的。具体实现的时候,记录一个candidate和其出现的次数count,遍历每个数,如果count==0,则把candidate置为遍历到的数,否则看遍历到的数和candidate是否相等,如果相等,则count++,否则count–(抵消),遍历结束后,candidate就是主元素。
进阶1:思路是,如果出现3个不一样的数,就抵消掉。记录两个candidate和每个candidate分别的出现次数。如果遍历到的数和两个candidate都不等,就count都减1。最后可能会剩下两个candidate,再遍历一次整个数组验证一下谁是主元素。
进阶2:思路是,如果出现k个不一样的数,就抵消掉。这里需要用巧妙的数据结构来记录Candidates,并使得如下操作均为O(1):
1. 加入一个Candidate/给某个Candidate出现次数+1
- Candidates中是否存在某个数
- Candidates中所有数的出现次数 - 1
- 移除出现次数为0的Candidates
对于1,2两个操作,我们自然可以想到使用Hash表来完成。对于第4两个操作,我们希望能够有出现次数最少的Candidate的信息,但是如果使用Heap则并非O(1)的时间复杂度。注意到每一次加入一个Candidate时,count均为1,每一次给改变一个Candidate出现次数时,也只涉及到加1运算。因此,如果我们能维护Candidates的有序性,就可以容易的解决这个问题。方法是,使用LinkedList。与普通的LinkedList不同的是,我们将所有出现次数相同的Candidate放在一个Bucket里,Bucket内部的Candidate用Doubly Linked List链接起来,Bucket之间也用Doubly Linked List链接起来。这样针对+1运算,我们只需要通过Hash表找到对应的Candidate,把Candidate从当前的Bucket移动到下一个Bucket(出现次数+1的Bucket)。另外,对于所有数-1的操作,我们记录全局的一个Base,每次-1操作,则Base+1。如果Base和Buckets中的第一个Bucket中的Candidates的出现次数相同,则整个删除第一个Bucket。最后,我们会得到最大k-1个Candidates,重新遍历一遍整个数组,用O(k)的Hash记录这k-1个Candidates的出现次数,就可以验证谁是真正的主元素。
面试官角度:
利用了抵消法的题目,还有“落单的数”(九章算法面试题1),同样是有进阶问题。对于进阶问题而言,关键是要理解“抵消”的思路,既然2个数可以抵消,那么3个数k个数也可以抵消。抵消之后,剩下来的数中,主元素一定仍然超过1/3, 1/k。对于1/k的情况(进阶2),其实在面试中一般来说不会问到,这个题的解法是源自一篇论文,所以不会做的同学也不必过于担心。但进阶1还是需要掌握的,因为进阶1说明是否真正理解了原问题的解法,还是只是背了答案。
论文参考:
E. D. Demaine, A. Lopez-Ortiz, and J. I. Munro. Frequency Estimation of Internet
Packet Streams with Limited Space. In Proceedings of the 10th
Annual European
Symposium on Algorithms, pages 348-360, 2002.
#hash#
#抵消法#
#哈希表#
#linkedlist#
#doublylinkedlist#
洗牌
有一副扑克有2n张牌,用1,2,..2*n代表每一张牌,一次洗牌会把牌分成两堆,1,2..n和n+1…2n。然后再交叉的洗在一起:n+1, 1, n+2, 2, … n, 2n。问按照这种技巧洗牌,洗多少次能够洗回扑克最初的状态:1,2,…2n。
答:
以1 2 3 4 5 6为例,洗一次之后为4 1 5 2 6 3 。将两排数组对比看:
1 2 3 4 5 6
4 1 5 2 6 3
数字1的下面是4,代表每一次洗牌后1这个位置的数会被4这个位置的数替代,接着看数字4,4下面是2,代表每一次洗牌后4这个位置的数会被2替代,再看2,2下面是1,2这个位置的数字会被1替代。此时,1 4 2形成一个环,代表这三个位置上的数再每一次洗牌后,循环交替,并且在洗3次以后,各自回到最初的位置。用同样的方法可以找到3 5 6是一个循环,循环节长度为3。由此可以知道,在经过了LCM(3,3)=3次洗牌后,所有数都回到原位,这里LCM是最小公倍数的意思。于是算法为,根据一次洗牌的结果,找到所有的循环节,答案为所有循环节长度的最小公倍数。
面试官角度:
这个题目的考察点在于找规律。不过如果有一定置换群的理论基础的同学,是可以比较轻松的解决这个问题的。有兴趣的同学可以查看离散数学的相关书籍中置换群的知识点。
#智力题#
#置换群#
分割数组
给一个数组A,和一个整数k,将数组分成两个部分(你可以移动数组中的数),使得左边部分的数都
答:
利用快速排序的思想。用两根指针i和j,一根指向头,一根指向尾,将头移动到第一个不满足A[i]
i, j = 0, len(A) -1
while i <= j:
while i < j and A[i] < k:
i += 1
while i < j and A[j] >= k:
j -= 1
if i <= j:
A[i], A[j] = A[j], A[i] #swap
i += 1
j -= 1
面试官角度
本题的考点是快排。如果写过快排或者明白快排的原理,很快就会明白这个题目只是快速排序中间的一个部分。两根指针一头一尾的这种方式,往期的题目中,第32题小球排序也是利用了类似的思路。读者可以将两个题目联系起来,找到共性,有利于思路的整理和归纳。
#数组#
#快排#
#array#
#快速排序#
#两根指针#
不用除法求积
给定一个数组A[1..n],求数组B[1..n],使得B[i] = A[1] A[2] .. A[i-1] A[i+1] .. A[n]。要求不要使用除法,且在O(n)的时间内完成,使用O(1)的额外空间(不包含B数组所占空间)。
答:
计算前缀乘积Prefix[i] = A[1] A[2] .. A[i],计算后缀乘积Suffix[i] = A[i] A[i+1] .. A[n],易知,B[i] = Prefix[i - 1] * Suffix[i + 1]。实际上无需实际构造出Prefix和Suffix数组,利用B数组从左到右遍历一次得到Prefix[i],然后从右到左遍历一次,计算出所要求的B数组。
面试官角度:
这种从前到后遍历和从后到前再遍历一次的方法(Foward-Backward-Traverse)在很多题目中都有借鉴。如九章算法面试题31 子数组的最大差。
判断单词的包含关系
给定两个单词A和B(假设均为小写字母,并且不含重复字母),判断A是否包含B。这里所定义的包含,只需要包含所有的字母即可,不要字母之间的顺序和邻接关系。要求想出尽可能多的方法(不限制复杂度)
答:
方法1:枚举法。对于单词A,枚举每个字母,看是否在B中出现,时间复杂度O(nm),空间复杂度O(1)。
方法2:哈希表。将A中字母序列转换为字母集合,判断B中每个字母是否在集合中。该集合的结构则是用哈希表实现。时间复杂度O(n+m),空间复杂度O(26)
方法3:二进制。可以用位运算替代方法2中的哈希表,用4字节整数的每一个二进制位代表某个字母是否出现过。时间复杂度O(n+m),空间复杂度O(1)
方法4:素数积。将a,b,c,d,e.. 对应到整数序列的若干素数2,3,5,7,11 …那么每个单词均可以用若干素数的乘积来代表。计算出A和B分别所对应的乘积,判断是否整除即可。时间复杂度O(n+m),空间复杂度O(26),缺点是需要高精度运算支持。
面试官角度:
方法包含但不限于上述四种。这个题目本身是十分简单的,难点在于你能想到多少种可行办法。考察的是求职者的思维是否活跃。上述的方法各有优劣。同时面试官也可能会跟面试者讨论,如果不限制在小写字母,不限制字符是否重复,算法该做如何的变化?
#字符串#
#单词#
#枚举#
#hash#
#哈希表#
#二进制#
#位运算#
构造MaxTree
给定一个没有重复元素的数组A,定义A上的MaxTree如下:MaxTree的根节点为A中最大的数,根节点的左子树为数组中最大数左边部分的MaxTree,右子树为数组中最大数右边部分的MaxTree。请根据给定的数组A,设计一个算法构造这个数组的MaxTree。
答:
如果能够确定每个节点的父亲节点,则可以构造出整棵树。找出每个数往左数第一个比他大的数和往右数第一个比他大的数,两者中较小的数即为该数的父亲节点。如:[3,1,2],3没有父亲节点,1的父亲节点为2,2的父亲节为3。并且可以根据与父亲的位置关系来确定是左儿子还是右儿子。接下来的问题是如何快速找出每个数往左、往右第一个比他大的数。这里需要用到数据结构栈。以找每个数左边第一个比他大的数为例,从左到右遍历每个数,栈中保持递减序列,新来的数不停的Pop出栈顶直到栈顶比新数大或没有数。以[3,1,2]为例,首先3入栈,接下来1比3小,无需pop出3,1入栈,并且确定了1往左第一个比他大的数为3。接下来2比1大,1出栈,2比3小,2入栈。并且确定了2往左第一个比他大的数为3。用同样的方法可以求得每个数往右第一个比他大的数。时间复杂度O(n),空间复杂度也是O(n)为最优解法。
面试官角度:
首先容易想到的是使用递归的方法来构造MaxTree,每一层递归用O(n)的时间找到最大数,然后将数组分为左右两个部分,然后递归完成构造。这种算法在极端情况下复杂度可能达到O(n^2),所以并不能被面试官所接受。但是你首先至少要把这种暴力的方法答出,并分析出最坏时间复杂度,因为这至少也体现出了你一部分的算法能力和时间复杂度分析的技巧。万一后面的正确方法答不出来,至少不会是0分。最优算法所使用到的Stack的方法,是一个非常常用的解题技巧。我们在今后的面试题中也会陆续为为大家讲解涉及到这种方法的题目。
#stack#
#栈#
#二叉树#
直方图内最大矩阵
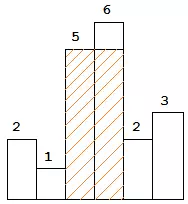
给出一个直方图(如图所示),求出所给直方图中所包含的最大矩阵面积。直方图可以用一个整数数组表示,如上图为[2, 1, 5, 6, 2, 3]。每个直方块的宽度均为1。上图中包含的最大矩阵面积为10.
答:
如果对于每个直方块,找到从它开始往左边数第一个比它小的,和往右边数第一个比他小的,则可以确定出以该直方块为最矮一块的矩阵的最大面积。使用数据结构栈,栈中保存递增序列,从左到右依次遍历每个数让其入栈,入栈之前先pop出所有>=该数的数,从而保持栈中的递增序列。pop完之后的栈顶元素即为该数往左边数第一个比他小的数。同理反过来遍历一次可以得到往右边数第一个比他小的数。时间复杂度O(n),空间复杂度O(n)
面试官角度:
计算每个数往左或往右数第一个比它大或小的数,这个应用场景则是数据结构栈的典型应用场景。我们在九章算法面试题42中的问题“构造MaxTree”也是用到了这种方法。因此,你需要记住在这种需求的情况下,使用栈可以使得时间复杂度和空间复杂度均为O(n)。直方图最大矩阵的问题,是面试中十分常见的问题,这个题目希望大家进行深入的学习,并编程实现。
#栈#
#stack#
#矩阵#
设计一个Web Crawler
如果让你来设计一个最基本的Web Crawler,该如何设计?需要考虑的因素有哪些?
答:
没有标准答案。需要尽可能的回答出多一点的考虑因素。
面试官角度:
这个问题是面试中常见的设计类问题。实际上如果你没有做过相关的设计,想要回答出一个让面试官满意的结果其实并不是很容易。该问题并不局限于你在去面试搜索引擎公司时可能会问到。这里,我们从Junior Level和Senior Level两个角度来解答这个问题。
如何抽象整个互联网
Junior: 抽象为一个无向图,网页为节点,网页中的链接为有向边。
Senior: 同上。抓取算法
Junior: 采用BFS的方法,维护一个队列,抓取到一个网页以后,分析网页的链接,扔到队列里。
Senior: 采用优先队列调度,区别于单纯的BFS,对于每个网页设定一定的抓取权重,优先抓取权重较高的网页。对于权重的设定,考虑的因素有:1. 是否属于一个比较热门的网站 2. 链接长度 3. link到该网页的网页的权重 4. 该网页被指向的次数 等等。进一步考虑,对于热门的网站,不能无限制的抓取,所以需要进行二级调度。首先调度抓取哪个网站,然后选中了要抓取的网站之后,调度在该网站中抓取哪些网页。这样做的好处是,非常礼貌的对单个网站的抓取有一定的限制,也给其他网站的网页抓取一些机会。网络模型
Junior: 多线程抓取。
Senior: 分别考虑单机抓取和分布式抓取的情况。对于Windows的单机,可以使用IOCP完成端口进行异步抓取,该种网络访问的方式可以最大程度的利用闲散资源。因为网络访问是需要等待的,如果简单的同时开多个线程,计算机用于线程间切换的耗费会非常大,这种用于处理抓取结果的时间就会非常少。IOCP可以做到使用几个线程就完成几十个线程同步抓取的效果。对于多机的抓取,需要考虑机器的分布,如抓取亚洲的站点,则用在亚洲范围内的计算机等等。实时性
Junior: 无需回答
Senior: 新闻网页的抓取一般来说是利用单独的爬虫来完成。新闻网页抓取的爬虫的权重设置与普通爬虫会有所区别。首先需要进行新闻源的筛选,这里有两种方式,一种是人工设置新闻源,如新浪首页,第二种方式是通过机器学习的方法。新闻源可以定义链接数非常多,链接内容经常变化的网页。从新闻源网页出发往下抓取给定层级限制的网页所得到,再根据网页中的时间戳信息判断,就可以加入新闻网页。网页更新
Junior: 无需回答。
Senior: 网页如果被抓下来以后,有的网页会持续变化,有的不会。这里就需要对网页的抓取设置一些生命力信息。当一个新的网页链接被发现以后,他的生命力时间戳信息应该是被发现的时间,表示马上需要被抓取,当一个网页被抓取之后,他的生命力时间戳信息可以被设置为x分钟以后,那么,等到x分钟以后,这个网页就可以根据这个时间戳来判断出,他需要被马上再抓取一次了。一个网页被第二次抓取以后,需要和之前的内容进行对比,如果内容一致,则延长下一次抓取的时间,如设为2x分钟后再抓取,直到达到一个限制长度如半年或者三个月(这个数值取决于你爬虫的能力)。如果被更新了,则需要缩短时间,如,x/2分钟之后再抓取。
一般来说,上述5点是你可以去回答如何设计一个爬虫的5个角度。
#web crawler#
#爬虫#
#设计#
#system design#
寻找最大的储水容器
#两根指针#
给定一个正整数数组(a0,a1..),分别代表n个坐标(0,a0), (1,a1),根据这n个点画出n条线段,每条线段的两个端点分别为(i, ai)和(i, 0)。找到两条线段,使得这两条线段和x轴所构成的容器储水容量最大。如[2,1,3], 最大,选择第一条线段和第三条线段,加上x轴所构成的容器,储水容量为4(高度为Min(2,3)=2,底为2)
答:
用两根指针,一根指向头,一根指向尾,如果A[head] > A[tail],意味着以tail为容器右边的最大容器面积为A[tail] (tail - head),记录下这个值,然后扔掉tail这条线段。同理如果A[head] < A[tail]我们可以记录下A[head] (tail - head),然后扔掉head。重复上述算法知道head与tail相遇。在过程中记录下来的面积中的最大值即为问题所求。时间复杂度O(n),空间O(1)
面试官角度:
在九章第42题和43题中,我们提到了使用栈来辅助计算每个数往左数or往有数比他大or小的“第一个”数。在该问题中我们不难分析出,我们需要寻找的是每个数往左数or往右数比他大的“最后一个”数。那么这和我们之前用栈的使用场景不符合。因此需要寻找其他的解决方案。两根指针的问题,是在数组面试题中用得比较多的思想。在今后的题目中,我们也会陆续介绍运用了类似思路的题目。
用栈实现队列
规定你只能使用数据结构栈(支持pop, push),怎么样用栈来模拟一个队列的pop和push?
提示:你可以使用多个栈。
要求:每个操作的均摊复杂度需要为O(1)
答:
使用两个栈,stack1和stack2。
对于Queue的操作对应如下:
Queue.Push:
push到Stack1
Queue.Pop:
如果Stack2非空,Stack2.pop
否则将Stack1中的所有数pop到Stack2中(相当于顺序颠倒了放入),然后Stack2.pop()
每个数进出Stack1和Stack2各1次,所以两个操作的均摊复杂度均为O(1)
队列上实现Min函数
在《九章算法面试题23 栈上实现Min函数》中,我们介绍了在栈上实现一个O(1)的Min方法。那么,如何在队列上实现一个Min方法?
要求,队列除了支持基本的Push(x) Pop()的方法以外,还需要支持Min方法,返回当前队列中的最小元素。每个方法的均摊复杂度为O(1)
答案:
在九章面试题49《用栈实现队列》和面试题23《栈上实现Min函数》中,我们讲解到了如何用栈实现队列和在栈上实现Min函数。那么将两个题的解法结合起来,就是如何在队列中实现Min函数。简要的步骤如下:
|
|
相关题目在线测试:
http://lintcode.com/zh-cn/problem/implement-queue-by-stacks/
http://lintcode.com/zh-cn/problem/min-stack/
二叉树的序列化
设计一个算法,序列化和反序列化一棵二叉树。
解释:序列化的意思是将内存中的一些特定的结构,变成有格式信息的字符串。如,对于链表而言,我们可以将1->2->3->NULL这样的链表序列化为”1,2,3”。对于序列化算法,必须支持反序列化,及在约定的格式下,可以将满足格式要求的字符串重新构造为想要的结构。在本题中,你需要同时实现一个序列化函数和反序列化函数。
答:
使用BFS。对于下面这棵二叉树:
BFS序为:[1,2,3,4,5]。如果我们将叶子节点的左右儿子用#来表示的话,可以得到下面这棵树:
一行一行看可以得到:[1,2,3,#,#,4,5,#,#,#,#]
去掉尾部连续的#,可以得到[1,2,3,#,#,4,5],这样就完成了使用BFS来序列化。
同样的,我们也可以使用DFS进行序列化,DFS序列化的结果如下:[1,2,#,#,3,4,#,#,5,#,#],去掉末尾的#得到[1,2,#,#,3,4,#,#,5],要比BFS序列化的结果要长。原因主要在于大部分的#出现在最底层,所以BFS的方式可以使得尽量多的#都在序列化的尾部。
反序列化的过程,这里就不多做说明了。
面试官角度:
所谓的序列化,是将一个结构化的东西变成扁平化的字符串。这样可以方便传输和进行压缩等。使用BFS或者DFS的方法在面试中都是正确的,但如果能够比较出BFS的方法可以更有效的节省空间的话,可以得到额外的加分。
数数字
本题的解法要诀在于熟练的使用递归思路和预处理。
预处理:
f[0] 代表了0-9中有多少个数字k。(肯定=1)
f[1] 代表了00-99中有多少个数字k。
f[2] 代表了000-999中有多少个数字k。
…
存在公式:f[i] = f[i-1] * 9 + 10i
g[1] 代表了10-99中有多少个数字k。
g[2] 代表了100-999有多少个数字k。
存在公式:g[i] = f[i] - f[i-1] // if k != 0
= f[i] - f[i-1] - 10i // if k ==0
令[a, b]代表a-b之间有多少个数字k。假设n=2345。
[0, 2345] = [0, 999] + [1000, 1999] + [2000, 2345]
这里[0, 999] = [0,9] + [10, 99] + [100, 999] = 1 + g[1] + g[2]
[1000, 1999] = [000, 999] = f[2] // k != 1
[000, 999] + 1000 = f[2] + 1000 // k == 1
[2000,2345] = [000, 345] // k!=2
= [000, 345] + 346 // k==2
[000,345] = [000, 099] + [100, 199] + [200, 299] + [300, 345]
= f[1] + 100 (k==0) + f[1] + 100 (k == 1) + f[1] + 100 (k == 2) + [00,45] + 46 (k == 3)
根据上面的分析,我们每次可以用O(1)的时间将带计算的n的位数减小一位:
从计算[0, 2345]到计算[000,345]到计算[00,45]。
因此整个算法的时间复杂度为O(log10(n))
第一个出错的代码版本
在早期的svn代码控制器中,代码版本的编号是从1开始累加的。有一天你提交了一个带BUG的代码到代码库中,使得这个版本上的单元测试(Unit Tests)失败了。而正不巧由于为此代码库贡献代码的每个人的工作都比较独立,你又休假去了,于是没有人去修复这个bug,这导致了从某个版本开始,后面的每个版本的单元测试都无法通过。假如说现在的代码版本号已经到了n。请找出第一个出错的代码版本(也就是你提交的那个有BUG的版本)。
你可以调用一个函数isBadVersion(id)去测试版本号id是否是一个可以通过Unit Tests的好版本。你的算法应该尽量少的调用isBadVersion这个函数。
在线评测本题:
http://lintcode.com/problem/first-bad-version/
解答:
采用简单的二分法可以解决。
|
|
带重复元素的全排列
给定一个带重复元素的整数集合,求出这个集合中所有元素的全排列。对于集合[1,1,2],其本质不同的全排列有三个,分别为:
[1,1,2]
[1,2,1]
[2,1,1]
在线测试你的程序正确性:
http://lintcode.com/problem/unique-permutations/
答:
首先做这个题目之前,要先会不带重复元素的全排列。
程序参考:http://www.ninechapter.com/solutions/permutations/
然后对于带重复元素的全排列,首先要对所有数排序,让重复的元素挤在一起。然后使用全排列的算法查找每一个排列。但是在构造每个排列的过程中加一句判断:
if (visited[i] == 1 || (i != 0 && num[i] == num[i - 1] && visited[i - 1] == 0)) {
continue;
}
这句判断的作用是,在选择重复的数的过程中,必须从第一个数开始取。如1 2 2。构造的时候,应该先选择第1个2,再选择第2个2。如果跳过第一个2选了第二个2,就会
旋转字符串
给一个字符串和一个旋转的偏移量offset,将字符串循环右移offset位。
如:”abcdefg” 循环右移 4位之后变为了:”defgabc”
要求做到O(1)的额外空间耗费,O(n)的时间
在线评测本题:
http://lintcode.com/problem/rotate-string/
解答
采用三步反转法。
以S=”abcdefg” offset=4为例子
首先将字符串看做:”abc”+”defg”
先整体反转:得到 “gfed” + “cba”
然后各自反转:得到“defg” + “abc” = “defgabc”
时间复杂度O(n),额外空间复杂度O(1)
最近公共祖先
给出一棵二叉树和两个二叉树上的节点,求出这两个点的最近公共祖先(Lowest Common Ancestor, LCA)。
如下面这棵二叉树:
1
/ \
2 3
/ \
4 5
4和5的最近公共祖先是3,2和4的最近公共祖先是1,1和3的最近公共祖先是1(假设自己是自己的祖先)
Follow Up Question 1: 如果树中的每个节点存储了自己的parent节点,算法应该是什么样的?
Follow Up Question 2: 如果树中的每个节点没有存储自己的parent节点,但给你这棵二叉树的根节点,算法应该是什么样的?
在线评测本题:
http://lintcode.com/problem/lowest-common-ancestor/
解答
对于有parent节点的二叉树,方法很简单,就是分别从两个节点网上列出到根的所有点,再反向查找第一个分叉的位置。
对于没有parent节点的二叉树,必须给出root。然后从root开始用分治算法往两边查找两个节点。如果有LCA就返回LCA,如果碰到其中一个点就返回其中一个点。
参考程序:
http://www.ninechapter.com/solutions/lowest-common-ancestor/
拷贝带随机指针的链表结构
给出一条带随机指针的链表,对其进行深度拷贝(Deep Copy)。
带随机指针的意思是,对于每个节点,除了next指针指向下一个节点以外,还带一个randomNext指针指向任何一个链表中的节点或空。
深度拷贝的意思是,对于新复制出来的链表,是一条完全独立于原来链表的链表,对于这个新的链表进行任何操作都不会对原来的链表产生影响。
Follow Up Question: 如果不能使用额外的辅助空间,算法该如何设计?
答案:
第一步:使用HashMap,首先复制所有的节点,用HashMap记录老节点A与新节点A’的映射关系。
第二步:遍历每个点,将Random指针连上。如存在一条Random指针从A指向B,那么在HashMap中找到映射的新节点A’和B’,将A’的Random指针指向B’。
额外空间复杂度O(n),时间复杂度O(n)
Follow Up 如果不适用额外的辅助存储空间:
第一步:将每个节点复制并插入相邻节点中。如1->2->3->NULL变为:1->1’->2->2’->3->3’->NULL。
第二步:接下来连接Random指针,如果存在一条Random指针从A指向B,那么将A->next的Random指针指向B->next。
第三步:将链表拆开。A=head, A’=head->next; A->next=A->next->next;A’->next=A’->next->next; …
时间复杂度O(n),额外空间复杂度O(1)
背包问题
有一个大小为m(整数)的背包,和n个体积为正整数的物品(大小分别为A[i])。将这个n个物品选一些装到背包中,请问最多能装满多少的体积?
在线评测本题:
http://www.lintcode.com/problem/backpack/
答案:
背包问题是动态规划问题的一种典型题目。 动态规划问题我们一般要考虑下面这四点。
状态 State
方程 Function
初始化 Intialization
答案 Answer
本题是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放,那下面我们来看背包这题动态规划的四点是怎么样的呢?
State: dp[i][S] 表示前i个物品,取出一些能否组成和为S体积的背包
Function: f[i][S] = f[i-1][S - A[i]] or f[i-1][S] (A[i]表示第i个物品的大小)
转移方程想得到f[i][S]前i个物品取出一些物品想组成S体积的背包。 那么可以从两个状态转换得到。
(1) f[i-1][S - A[i]] 放入第i个物品,并且前i-1个物品能否取出一些组成和为S-A[i] 体积大小的背包。
(2) f[i-1][S] 不放入第i个物品, 并且前i-1个物品能否取出一些组成和为S 体积大小的背包。
- Intialize: f[1…n][0] = true; f[0][1… m] = false
初始化 f[1…n][0] 表示前1…n个物品,取出一些能否组成和为0 大小的背包始终为真。
其他初始化为假
- Answer: 寻找使f[n][S] 值为true的最大的S. (S的取值范围1到m)
由于这道题空间上有一些要求,所以在知道了思路答案过后我们还需要进行优化空间复杂度.先考虑上面讲的基本思路如何实现,肯定是有一个主循环i=1..N,每次算出来二维数组f[i][0..S]的所有值。那么,如果只用一个数组f[0..S],能不能保证第i次循环结束后f[S]中表示的就是我们定义的状态f[i][S]呢?f[i][S]是由 f[i-1][S - a[i]] 和 f[i-1][S] 两个子问题递推而来,能否保证在推f[i][S]时(也即在第i次主循环中推f[S]时)能够得到 f[i-1][S - a[i]] 和 f[i-1][S] 的值呢?事实上,这要求在每次主循环中我们以S=m…0的顺序推f[S],这样才能保证推f[S]时f[S-a[i]]保存的是状态f[i-1][S-a[i]]的值。伪代码如下:
for i=1..N
for S=m…0
f[S]=f[S] or f[S-a[i]];
背包问题II
有一个大小为m(整数)的背包,和n个体积(大小分别为Ai)和价值(价格分别为Bi)的物品。将这n个物品选一些装到背包中,请问能装价值最大为多少的物品?
在线练习本题:
http://www.lintcode.com/en/problem/backpack-ii/
答:
设F[i][j]为前i个物品,选一些组成j的体积,能够获得最大的价值是多少。
状态转移方程:f[i][j] = max(f[i-1][j], f[i-1][j-A[i]] + B[i])
答案为F[n][0..m] 中取一个最大值。
面试官角度:
背包问题是比较常见的面试问题之一。一般来说常见的背包问题的解法需要熟知和熟练。
以下是几道背包问题的在线练习:
http://www.lintcode.com/zh-cn/problem/backpack/
http://www.lintcode.com/zh-cn/problem/backpack-ii/
http://www.lintcode.com/zh-cn/problem/minimum-adjustment-cost/
爬楼梯
有n层的台阶,一开始你站在第0层,每次可以爬两层或者一层。请问爬到第n层有多少种不同的方法?
Follow Up Question: 如果每次可以爬两层,和倒退一层,同一个位置不能重复走,请问爬到第n层有多少种不同的方法?
答:这道题属于简单的数组一维动态规划
State:f[i] 表示爬到第i层的方法数目。
Function: f[i] = f[i-1] + f[i-2] 第i层的方法数目等于第i-1层数目加上第i-2层数目
Intialize: f[0] = 1, f[1] =1 初始化 最开始没有爬和第一层的方法数目为1.
Answer: f[n] 爬到第n层有多少种不同的方法
Follow Up Question:
这道题与原来的题相比提升了一个难度,主要是倒退一层,这个地方可能会违背动态规划无后效性的原则。 那么我们要怎么转化呢?
由条件:同一个位置不能重复走。我们可以知道如果要退步的话,不能退两层以上,因为用两步退两层再一步前进两层,那就会走相同的位置。所以我们最多只能退后一步。
那么题目的条件就可以转换两种情况,
a.跳两层(前进两层)。
b.退一层跳两层 (前进一层)。
State:f[i][0] 表示最后一步是跳两层情况下爬到第i层的方法数目。f[i][1] 表示最后是一步是退一层跳两层的情况下爬到第i层的方法数目。
Function: f[i+1][1] = f[i][0] 最后一步是退一层跳两层的情况下爬到第i+1层的方法数目等于从第i层情况a的数目跳两层退一层。这里不能考虑第i层的情况b的方法数,因为第i层情况b的数目是从第i+1层退一步得到的。
f[i+2][0] = f[i][0]+f[i][1] 最后一步是退一层跳两层的情况下爬到第i+2层的方法数目等于第i层所有情况跳两层。
Intialize: f[0][0]=1初始化最开始没有爬的方法数目为1.
Answer: f[n][0]+f[n][1] 爬到第n层a、b两种不同的方法的总和
在线测试本题:
http://www.lintcode.com/problem/climbing-stairs/
克隆图
给出一个图,并且给出图的起始节点,知道这个图的节点的定义,要求克隆这个图,返回克隆图的起始节点。
在线测试本题:
http://www.lintcode.com/en/problem/clone-graph/
合并k个排序数组
给出K个排序好的数组,用什么方法可以最快的把他们合并成为一个排序数组?
在线测试本题:
http://lintcode.com/en/problem/merge-k-sorted-lists/
答案:
这中题目分布式系统经常运用到,比如来自不同客户端的排序好的链表想要在主服务器上面合并起来。
一般这种题目有两种做法。
第一种做法比较容易想到,就是有点类似于MergeSort的思路,就是分治法。先把k个list分成两半,然后继续划分,知道剩下两个list就合并起来,合并时会用到类似 Merge Two Sorted Lists 这道题的思路。 这种思路我们分析一下复杂度,如果有k个list,每个list最大长度是n,那么我们就有分治思路的复杂度计算公式 T(k) = 2T(k/2)+O(n*k)。 其中T(k)表示k个list合并的时间复杂度,用主定理可以算出时间复杂度是O(nklogk)。
第二种做法是运用堆,也就是我们所说的priority queue。我们可以考虑维护一个大小为k的堆,先把每个list的第一个元素放入堆之中,然后每次从堆顶选取最小元素放入结果最后的list里面,然后读取该元素所在list的下一个元素放入堆中,重新维护好堆,然后重复这个过程。因为每个链表是有序的,每次又是取当前k个元素中最小的,所以最后结果的list的元素是按从小到大顺序排列的。这种方法的时间复杂度也是O(nklogk)。
最大的数( leetcode/lintcode新题 )
现在有一串非负的数组,把他们重新排序组合在一起,组成一个整数,请问如何排序组合在一起是使组成的数最大。例如:数组[3, 30, 34, 5, 9],通过重新排序组合在一起的最大整数是9534330。
在线测试本题:
http://lintcode.com/en/problem/largest-number/
答案:
方法一:
这道题的关键在于怎么确定每个数在最后结果中的排列位置,大家第一步想到的是肯定是第一位数越大的越靠前,如8在6, 5之前;
如果第一位相同的情况出现那么再看第二位,比如下面这个例子[4,45,40]中, 45应当在40之前;
难点是位数不等的情况下,先后关系怎么确定?如4应当放在40和45之前、之后还是中间?结果是4放在了45和40中间,为什么呢?这是因为十位上的4比个位上0大,所以4在40之前。
通过这样的方法,虽然可以找出个先后顺序,但是还需考虑其他的情况,太复杂了。
方法二:
我们为什么不直接比较一下不同组合的结果大小?
比如说:可以通过比较445和454的大小来确认4和45的先后位置,由于454比445大,所以45应当在前。
所以可以通过比较两个数的方法, 来排序这个数组里面的所有的元素然后把他们拼接在一起。通过这样的方法我们不就可以找到最后的答案了么?
快速幂
计算(a^n)%b,其中a,b和n都是32位的整数。 例如 (2^31)%3 = 2。
线测试本题:
http://lintcode.com/zh-cn/problem/fast-power/
答案:
首先我们要知道mod运算的一个定理:
(a b) % p = (a % p b % p) % p
由这个定理我们可以知道
原来a^n % b
1.如果n 为奇数可以转化为 (a^(n/2) a^(n/2) a ) %b = ((a^(n/2)%b a^(n/2)%b)%b (a)%b) %b
- 如果n 为偶数可以转化为 (a^(n/2) a^(n/2) ) %b = (a^(n/2)%b a^(n/2)%b)%b
由于知道a^1 = a , a^0=1 ,
然后递归的去求a^n ,这样我们每次就二分n,那么我们的实际的时间复杂度是O(log(n))。
所以当n特别大的话,那么求幂就会变得特别快。
找第k大的特殊数
题目
有一种特殊的数,它的素数因子只有可能是3,5,7,不可能是其他的素数, 我们把这种数从小到大排序,得到3,5, 7, 9, 15 … 现在我们要求其中第K大得数是多少,比如其中第4大的数是9。
在线测试本题
http://t.cn/RAQr6tz
答案
我们所要求的元素如果除以3,5,7然后排序过后可以分成为三类元素。
a. 1×3, 3×3, 5×3, 7×3,9×3, …
b. 1×5, 3×5, 5×5, 7×5, 9×5, …
c. 1×7, 3×7, 5×7, 7×7, 9×7,…
最后其实相当于是把三个数列merge到一起,然后找出这个merge数列的第k大,并且分解后相乘的两个数中的第一个元素刚好是我们所求的数列,然后第二个数是3,5,7。 我们知道merge三个数列的算法是用三个指针,所以我们可以借鉴这种merge的做法 。我们设三个指针p3,p5,p7,最开始p3=0,p5=0,p7=0, 然后用一个数组a记录我们要求的数列。最开始数列第一个元素是a[0]=1 ,然后每次选取(a[p3]3,a[p5]5, a[p7]*7)中最小的元素作为下一个元素插入到数组a中,如果最小的元素是p3,那么p3指向下一个元素p3++, 同理如果是p5, p5++ , 如果是p7那么p7++ , 所以第k步的时候,a[k]就存储了我们所求的元素。 这样最后这道题的时间复杂度就是O(n)。
拓扑排序
题目
给一个有向无环图,求出这个有向无环图的拓扑排序结果。
在线测试本题
http://t.cn/RAQrJdr
背景知识
拓扑排序问题在我们生产工序或者是建立依赖关系当中有重要的运用。
通常我们所说的拓扑排序是对一个有向无环图的。 所以把一个有向无环图的顶点组成的序列,每个点只出现一次,并且A在序列中排在B的前面图中不存在从B到A的路径的序列叫做这个图的拓扑排序。
一般来说拓扑排序不一定只有一种。 比如这道题拓扑排序就有[0, 1, 2, 3, 4, 5], [0, 2, 3, 1, 5, 4] 等
入度的意思是有向图中,一个点有N个边指向这个点,那么它的入度就是N, 比如题中1的入度就是1,4的入度就是2
出度度的意思是有向图中,一个点有N个边指向其他的点,那么它的出度就是N, 比如题中0的入度就是3,2的入度就是2
答案
对于拓扑排序来说, 我们的中心思想是要我们可以找到一个顺序,每一次我们可以进行的工序是现在没有先序依赖的工序,按照这个顺序可以流畅的完成我们的任务。如果从图论的角度来说,实际上是从一个点遍历整个图,并且遍历图的时候,下次可以遍历的点是入度为0的点, 而我们遍历的顺序就是我们所要求的拓扑排序的顺序。
那么我们既然要遍历一个图,那么我们可以用宽度优先的方法,因为宽度优先的方法非常适合通过一点去遍历整个图,只不过对于求拓扑排序的问题,我们宽度优先搜索有一个条件就是每一次只能遍历当前入度为0的点,也就是说宽度优先所有的队列中只能放入入度为0的点,然后每次遍历一个点之后,就更新这个点相邻的点的入度信息,因为遍历了这个点,相当于相邻的点的依赖前序工序减少了1个,也就是相邻点的入度减少了1,如果相邻点中更新后有入度为0的点,那么我们就把相邻点放入到队列当中以便下一次进行访问。
通过这样的方法我们遍历一遍整个图。用O(m),m为图的边数,的时间复杂度就可以求出这个图的拓扑排序解。
2 Sum
题目
给一堆数组和一个目标值,在这堆数组里面找出两个数使得他们的和等于目标值。
在线测试本题
http://t.cn/RAnyOUN
答案
如果原题的数组中第i个元素我们用ai来表示,目标值我们用v来表示。
这道题有两种方法可以解:
方法一:
既然是需要找两个数使得他们的和为目标值, 一说到查找我们就会想到hash,因为hash可以帮助我们加快查找方法。 然后我们可以for循环扫一遍我们的数组,并且hash表存储在扫到第i个数时候,前面扫过的i-1个数。 这样我们找的其实是前面有没有一个元素和第i个数ai 相加为v , 那么我们只用在hash表里面去查找有没有v-ai这个元素如果有,那么就说明前面i-1个数中有一个数加上ai 他们的和为v. 这种方法的时间复杂度是O(n),空间复杂度是O(n)。
方法二:
这种方法叫做两个指针,我们可以先把数组排序,然后两个指针分别指向数组一头一尾数组最大和最小的元素,我们把这两个指针叫做front和end。 如果a[front] + a[end] > v, 那么说明front右边所有的元素+end的值都会大于v,所以我们不需要考虑这些元素了。所以只用把end-1,也就是end指针向有数组左边移动。 如果a[front] + a[end] < v,那么说明end左边所有的元素+end的值也都会小于v,所以我们也不用考虑这些元素了。所以只用把front+1,也就是front指针向数组右边移动。 这样一直循环到front指针=end指针停止。用这种方法我们就可以找到两个指针使得他们的和等于v。 这种方法的时间复杂度是O(nlogn+n) , 空间复杂度是O(1).
3 Sum
题目
给一堆数组和一个目标值,在这堆数组里面找出三个数使得他们的和等于目标值。
在线测试本题
http://t.cn/RA35IT5
答案
如果原题的数组中第i个元素我们用ai来表示,目标值我们用v来表示。
这道题的方法非常类似2 sum的第二种解法。首先我们还是先把数组排一个顺序, 然后我们现在还是需要三个指针i,j,k, 我们假设i<j<k,因为我们排了序,那么a[i]<a[j]<a[k], 实际上题意可以转换为a[i]+a[j]+a[k]=v. 我们如果枚举i的话,那么题意又可以转换为在大于a[i]的元素当中寻找a[j]+a[k] = v-a[i] ,那么这个问题就是2sum的问题,所以我们可以用2sum 两个指针指向一头一尾的方法解决这道题。
4 sum
题目
给一堆数组和一个目标值,在这堆数组里面找出四个数使得他们的和等于目标值。
在线测试本题
http://t.cn/RA35IT5
答案
方法一:
这道题的方法也非常类似2 sum的第二种解法。首先我们还是先把数组排一个顺序, 然后我们现在还是需要四个指针i,j,x,y, 我们假设i<j<x<y,因为我们排了序,那么a[i]<a[j]<a[x]<a[y], 实际上题意可以转换为a[i]+a[j]+a[x]+a[y]=v. 我们如果枚举i,j的话,那么题意又可以转换为在大于a[j]的元素当中寻找a[x]+a[y] = v-a[i]-a[j] ,那么这个问题就是2sum的问题,所以我们可以用2sum 两个指针指向一头一尾的方法解决这道题。
方法二:
这道题还有另一个方法,就是先可以用一个hash表记录数组当中任意两个数的和sum = a[x]+a[y],并且记录是哪两个数的和, 这样用o(n^2)的时间复杂度就可以记录任意两个数的和,然后在用两个指针i,j(i<j)遍历数组, 然后在hash表中寻找v-a[i]-a[j]是否存在,并且保证a[i],a[j],a[x],a[y] 不能取相同的数,然后通过i,j两层for循环就可以找到4sum
Sort Colors
题目
给一个数组,并且数组里面元素的值只可能是0,1,2,然后现在把这个数组排序
在线测试本题
http://www.lintcode.com/en/problem/sort-colors/
解答
这道题one pass的方法需要用two pointer的技巧。 用两个指针,一个指针x指向数组头便是0和1的区分的位置, 另一个指针y指向尾表示1和2的区分的位置,然后我们在遍历一遍数组,如果当前遇到的元素是0,那么我们就把它和x指向位置的元素调换,并且x前进一步,更新边界;如果是1,那么不变;如果是2,那么把它y指向的位置的元素调换,并且y后退一步,这样就可以保证x是0和1区分的位置,y是1和2区分的位置。 这种方法时间复杂度O(n),空间复杂度O(1)
Sort Colors II
题目
给定一个有n个对象(包括k种不同的颜色,并按照1到k进行编号)的数组,将对象进行分类使相同颜色的对象相邻,并按照1,2,…k的顺序进行排序。
在线测试本题
http://www.lintcode.com/zh-cn/problem/sort-colors-ii/
答案
这道题有两种方法。
方法一: 可以借助一个O(k)的数组bucket,然后扫一遍原来的数组,统计每一种颜色有多少个存放在数组bucket里面,然后题目要求把颜色排序,其实就是再把b里面的统计重新输出到原来的数组就好了。
方法二: 题目要求不使用额外的数组,可以利用上面的思想,只不过要用原来的数组a来统计每个颜色出现的频率。由于原来的颜色肯定是正数1-k,所以我们可以用负数比如a[i]=-k,表示第i种颜色在原来的数组里面出现了k次。这道题原数组还要重复利用作为bucket数组,那么我们应该怎么办呢?首先for循环遍历一遍原来的数组,如果扫到a[i],首先检查a[a[i]]是否为正数,如果是把a[a[i]]移动a[i]存放起来,然后把a[a[i]]记为-1(表示该位置是一个计数器,计1)。 如果a[a[i]]是负数,那么说明这一个地方曾经已经计数了,那么把a[a[i]]计数减一,并把color[i] 设置为0 (表示此处已经计算过),然后重复向下遍历下一个数,这样遍历原数组所有的元素过后,数组a里面实际上存储的每种颜色的计数,然后我们倒着再输出每种颜色就可以得到我们排序后的数组。
平方根
题目
给定一个数,怎么样不用系统函数sqrt,可以求得它的平方根的答案。
在线测试本题
http://www.lintcode.com/en/problem/sqrtx/
答案
这道题目我们有两种方法:
方法一: 二分法。 我们知道假使y表示x的平方根的值,那么可以确定0<=y
方法二: 牛顿迭代法。 计算x^2 = n的解,令f(x)=x^2-n,相当于求解f(x)=0的解。首先先取一个点x0为一个较大的数, 如果x0不是解,做一个经过(x0,f(x0))这个点的切线,与x轴的交点为x1,看x1是不是解。如果不是,那么继续做一个经过(x1,f(x1))这个点的切线与x轴的交点为x2,然后看x2是不是解。然后一直重复这个过程,经过(xi, f(xi))这个点的切线方程为f(x) = f(xi) + f’(xi)(x - xi),其中f’(x)为f(x)的导数,本题中为2x。令切线方程等于0,即可求出xi+1=xi - f(xi) / f’(xi)。有了迭代公式,就可以用迭代公式无限逼近,求最后方程的解。
继续化简,xi+1=xi - (xi2 - n) / (2xi) = xi - xi / 2 + n / (2xi) = xi / 2 + n / 2xi = (xi + n/xi) / 2。
翻转链表 II
题目
给一个链表,然后我们要把这个链表中第m个节点到第n个节点的部分翻转。
http://www.lintcode.com/en/problem/reverse-linked-list-ii/
答案
为更好处理表头和第m个节点,引入dummy结点,因为头节点可能被翻转,dummy node使得头节点的翻转和普通节点翻转操作一样。由于我们翻转的是第m个节点到第n个节点,并且第m-1个节点的next指针会改变,第n个节点指向n+1节点的next指针会改变,所以我们只用考虑m-1到n+1个节点。然后,先可以用翻转链表I的方法,翻转第m个到第n个节点,然后把m-1节点的next指针指向新m节点,第n个节点的next指针指向n+1节点,以避免链表断裂。
中位数
题目
给定一个未排序的整数数组,找到其中位数。
中位数是排序后数组的中间值,如果数组的个数是偶数个,则返回排序后数组的第N/2个数。
在线测试本题
http://www.lintcode.com/zh-cn/problem/median/
答案
这道题可以用快速选择一个类似快速排序的方法。如果数组长度为n,这道题求中位数实际上可以转化为求整个数组当中第(n+1)/2大的数,每次选择数组里面最左边的元素然后把数组里面比它大的放在数组它右边,比它小的放在左边,然后知道这个元素是在整个数组当中的第x大.如果x<(n+1)/2, 那么可以这个元素右边的数组里面找第(n+1)/2大,如果是x>(n+1)/2,那么在这个元素左边的数组里面找第(n+1)/2大。以此递归的查询。 直到x 等于(n+1)/2 停止递归。 我们采用这种方法的均摊时间复杂度为O(n).
二叉树的最小深度
题目
给定一个二叉树,找出其最小深度。
二叉树的最小深度为根节点到最近叶子节点的距离。
在线测试本题
http://www.lintcode.com/zh-cn/problem/minimum-depth-of-binary-tree/
解答
方法一:递归。
这道题可以用递归的方法,一个节点一个节点的把每个节点遍历一遍,并且在遍历的同时记录每个节点相对应的层数, 然后求出叶子节点当中的最小层数就是我们所求的答案。
方法二:非递归。
非递归的方法也就是用宽度优先搜索一层一层树上去遍历节点,当第一次遍历到树上的叶子节点的时候就是我们所要找到的二叉树的最小深度。
搜索二维矩阵
题目
写出一个高效的算法来搜索 m × n矩阵中的值。
这个矩阵具有以下特性:
每行中的整数从左到右是排序的。
每行的第一个数大于上一行的最后一个整数。
在线测试本题
http://www.lintcode.com/zh-cn/problem/search-a-2d-matrix/
答案
这道题虽然看似矩阵问题,其实最终可以转换为一维数组,每一行按照顺序已经排好序了同时上一行末尾的元素比下一行第一个元素大, 那么其实可以依次把上一行的末尾接在下一行数组前面,这样最后我们就把二维矩阵转化为一维的排序数组,而二维矩阵第i行第j列,在一维数组的第i*m+j个位置, 然后由于一维排序数组已经排序好,所以我们只用2分查找在一维排序数组里面找到相对应的值就好。
插入区间
题目
给出一个无重叠的按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
在线测试本题
http://www.lintcode.com/zh-cn/problem/insert-interval/
答案
这道题主要考察的是细节处理的过程, 因为插入后的区间可能会出现三种可能。1, 在头插入,2,在中间插入,3,在尾插入。 第1,3好处理,直接判断是在头还是在尾,直接加入就好。 然后第2种需要判断插入后的区间是否可以和其他的区间合并。 所以要扫描一遍,判断他前后有没有可以合并的区间,然后把他们合并在一起。
有效回文串
题目
给定一个字符串,判断其是否为一个回文串。只包含字母和数字,忽略大小写。
在线测试本题
http://www.lintcode.com/zh-cn/problem/valid-palindrome/
解答
这道题其实是一道常见的细节考察题,虽然看似不太难,但是却有几个坑点需要考虑,如果能够完整考虑到坑点的话, 那么才能做到写这道题的时候bug free.
从算法细节来说,这道题无非是一道两个指针的题目,指针为对撞型指针, 一个指针指向头,一个指针指向尾,每次比较头指针指向的元素和尾指针指向的元素是否相等,如果一直到头指针和尾指针相遇的时候那么这个字符串就是回文字符串。
你以为这样就解决这道题了么?
其实不然。
还需要考虑的如下几个细节:
遇到非字母和数字只用跳过就好。
字符串有可能是空字符串,所以要考虑空串的情况。
寻找峰值
题目
你给出一个整数数组(size为n),其具有以下特点:
相邻位置的数字是不同的
A[0] < A[1] 并且 A[n - 2] > A[n - 1]
假定P是峰值的位置则满足A[P] > A[P-1]且A[P] > A[P+1],返回数组中任意一个峰值的位置。
在线测试本题
http://www.lintcode.com/zh-cn/problem/find-peak-element/
解答
最简单地解法就是遍历数组复杂度为O(N),只要找到第一个元素,大于两边就可以了,但这题还可以用更优化的二分搜索来做。
首先我们的目标是找到中间节点mid, 1.如果大于两边的数字那么就是找到了答案,直接返回找到的答案。 2. 如果左边的节点比mid大,那么我们可以继续在左半区间查找,因为左边可以证明一定存在一个peak element, 为什么呢?因为题目告诉了我们区间[0, mid - 1] 中num[0] < num[1],我们刚才又知道num[mid - 1]>num[mid]了,所以[0, mid - 1] 之间肯定有一个peak element。 3. 如果num[mid - 2] > num[mid - 1],那么我们就继续在[0, mid - 2]区间查找,那么同理可以在右边的区间找到一个peak element。所以继续这个二分搜索的方式最后我们就能找到一个peak element。
接雨水
题目
给出 n 个非负整数,代表一张X轴上每个区域宽度为 1 的海拔图, 计算这个海拔图最多能接住多少(面积)雨水
在线测试本题
http://www.lintcode.com/zh-cn/problem/trapping-rain-water/
解答
这道题可以有两种做法。
做法一:扫两遍。 对某个值A[i]来说,能trapped的最多的water取决于在i之前左边的最高值和在i右边的最高的值,然后取当中较小的一个。 所以可以根据上面的分析先从左到右扫一遍得到数组LeftMostHeight,然后再从右到左计算RightMostHeight,这样只扫了两遍可以得到答案,时间复杂度是O(n),空间复杂度是O(n)。
做法二:两个指针扫一遍, 这道题其实是一道两个指针的题目,而且指针属性是对撞型指针。 所以用两个指针分别指向数组的头和数组尾。 然后每次比较两个指针所指向的值,选小值指针向中间移动,并且每次更新遍历LeftMostHeight或者RightMostHeight, 这样就可以算出每个点的可以接的雨水数目。 这种方法的时间复杂度是O(n)。空间复杂度是O(1)。
岛屿的个数
题目
给一个01矩阵,求不同的岛屿的个数。
0代表海,1代表岛,如果两个1相邻,那么这两个1属于同一个岛。我们只考虑上下左右为相邻。
在线测试本题
http://www.lintcode.com/zh-cn/problem/number-of-islands/
解答
两重循环遍历1的位置,然后从这个位置开始进行深度搜索DFS,向上下左右走,将碰到的1,都变成0。每进行这样的一次DFS,岛屿的计数就+1。最后得到岛屿个数。
合并有序链表
题目
合并两个有序链表,要求合并之后依然有序。
在线测试本题
http://www.lintcode.com/problem/merge-two-sorted-lists/
解答
模拟就好了
把0移到数组右边
题目
把一个数组中的0移动到数组的左边。
在线测试本题
http://www.lintcode.com/problem/partition-array/
解答
这道题是正宗两个指针中对撞型指针的问题, 一个指针指向数组最左边,一个指针指向最右边, 然后向中间移动,左指针找到比k大的元素,右指针找到比k小的元素, 然后swap 一下两个指针现在指向的元素,之后他们继续重复上面的操作,当两个指针指向同一元素的时候停止上述操作。
奇偶分割数组
题目
奇偶分割数组。
在线测试本题
http://www.lintcode.com/en/problem/partition-array-by-odd-and-even/
解答
这一类的题目是两个指针的题目,并且是对撞型指针。
用两个pointer分别从两头向中间靠拢,左边的指针从左往右找到第一个偶数,右边的指针从右往左找到第一个奇数, 然后交换两个指针所指向的元素,这样就可以保证, 左边一个指针维护左边所有的元素是奇数,右边一个指针维护所有的元素是偶数。
搜索区间
题目
给定一个包含 n 个整数的排序数组,找出给定目标值 target 的起始和结束位置。
如果目标值不在数组中,则返回[-1, -1]
在线测试本题
http://www.lintcode.com/zh-cn/problem/search-for-a-range/
解答
这道题既然要求O(log n)那必然和binary search相关。那么题目其实上是要找到给出的target区间[left,right]在数组中的左右边界。我们用二分,分别找到left和right在数组里面对应的左边界和右边界。
二分的方法如下:
对搜索left:如果left >= A[mid]则继续向左找,否则向右找。直到搜索结束,left = start
对搜索right:如果right <= A[mid]则继续向右找,否则向左找。直到搜索结束,right = end
最后判断如果A[left], A[right] != target,则表明target不存在于数组中, left = right = -1
合并排序数组
题目
合并两个排序的整数数组A和B变成一个新的数组。
在线测试本题
http://www.lintcode.com/zh-cn/problem/merge-sorted-array-ii/
解答
这道题是两个数组两个指针的题目。由于两个数组已经排序好了。 所以只需要两个指针分别指向两个数组,然后取两个小指针指向数当中比较小的那个然后从那个数组当中选出小的数,然后相应的指针指向下一个元素。 两个指针扫完数组之后,他们就相应的合并到一起了。
最小子数组
题目
给定一个整数数组,找到一个具有最小和的子数组。返回其最小和。
在线测试本题
http://www.lintcode.com/zh-cn/problem/minimum-subarray/
解答
这道题和max subarray很类似,我用local 和 global 的dp方式阔以解决这道
那么我们来看动态规划的四个要素分别是什么?
State:
localmin[i] 表示以当前第i个数最为结尾的最小连续子数组和。
globalmin[i] 表示以当i个数里面(可以不以第i个作为结尾)的最小连续子数组和。
Function:
localmin[i] = min(localmin[i - 1] + nums.get(i), nums.get(i));
globalmin[i] = min(globalmin[i - 1], localmin[i]);
initialize:
globalmin[0] = localmin[0] = nums.get(0);
answer:
globalmin[n-1]/
优化:
由于这道题第i个状态只跟i-1的状态有关,所以这道题还可以用滚动数组
最多有多少个点在一条直线上
题目
给出二维平面上的n个点,求最多有多少点在同一条直线上。
在线测试本题
http://www.lintcode.com/zh-cn/problem/max-points-on-a-line/
答案
每次取定一个点x,然后对其他所有的n-1个点和点x做斜率,并统计斜率相同的数目,取其中最大值即可。
这里要注意2个地方:
1)考虑重复点的情况,重复点是无法计算斜率的;
2)考虑直线与y轴平行时,斜率为无穷大的情况。所以要特殊处理。
中位数II
题目
数字是不断进入数组的,在每次添加一个新的数进入数组的同时返回当前新数组的中位数。
在线测试本题
http://www.lintcode.com/zh-cn/problem/data-stream-median/
解答
这道题是堆解决的问题。
用两个堆, max heap 和 min heap,在加一个median值, 维持两个堆的大小相等(max堆可以比min堆多一个). 对于新来的元素,比较新元素和median的大小,如果大于median就放入最小堆里面,如果小于median就放入最大堆里面,如果max heap,和min heap不平衡了,就调整一下。 然后调整过后median 里面的值就是我们要求的中位数。
最长单词
题目
给一个词典,找出其中所有最长的单词。
在线测试本题
http://www.lintcode.com/zh-cn/problem/longest-words/
解答
遍历两次的办法很容易想到,只遍历一次就比较难实现。 这里我们主要讲怎么遍历一次。 可以记录一个变量len表示现在最长的字符串的长度,然后一个arraylist 保存现在等于len那么长的单词。 从头开始遍历整个字典。如果遇到某个单词的长度大于len,那么就更新len,并且清空arraylist把新的单词放入arraylist里面;如果遇到某单词长度等于len,那么就加入arraylist; 如果遇到某单词长度小于len,那么就直接略过。
这样就通过扫一遍,然后最后在arraylist里面保存的单词就是我们要的答案。
拓扑排序
给定一个有向图,图节点的拓扑排序被定义为:
对于每条有向边A–> B,则A必须排在B之前
拓扑排序的第一个节点可以是任何在图中没有其他节点指向它的节点
找到给定图的任一拓扑排序
在线测试本题
http://www.lintcode.com/zh-cn/problem/topological-sorting/
解答
对于这道题首先要知道只有有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
那么对于一个DAG怎么求得他的拓扑序呢?
从 DAG 图中选择一个入度为0 的顶点并输出。
从图中删除该顶点和所有以它为起点的有向边。
重复 1 和 2 直到当前的 DAG 图为空或当前图中不存在无前驱的顶点为止。后一种情况说明有向图中必然存在环。
复制带随机指针的链表
题目
给出一个链表,每个节点包含一个额外增加的随机指针可以指向链表中的任何节点或空的节点。
返回一个深拷贝的链表。
在线测试本题
http://www.lintcode.com/zh-cn/problem/copy-list-with-random-pointer/
解答
这道题要我们拷贝链表和随机指针。 一般拷贝问题可以分为两个,第一个是拷贝点, 第二个拷贝指针关系。 对于这道题。 我们可以先拷贝一下链表当中的每个点的克隆点。 然后用一个hash 表来存储一下。然后第二遍再遍历一下。然后一边遍历的时候一边通过第一次存储的hash表,去找到克隆点与克隆点之间关系,然后拷贝指针。
颠倒整数
题目
将一个整数中的数字进行颠倒,当颠倒后的整数溢出时,返回 0 (标记为 32 位整数)。
在线测试本题
http://www.lintcode.com/zh-cn/problem/reverse-integer/
解答
这道题主要坑点在于负数和溢出两种情况。
首先如果是一般情况,那么我们就只需要,按照每一位,一位一位的翻转。然后如果是负数,那么要先判断负号了后在翻转。 如果是溢出的情况那么我要直接返回0.
找出有向图中的弱相连节点
题目
请找出有向图中弱联通分量的数目。图中的每个节点包含其邻居的 1 个标签和1 个列表。 (一个有向图中的相连节点指的是一个包含 2 个通过直接边沿路径相连的顶点的子图。)
在线测试本题
http://www.lintcode.com/zh-cn/problem/find-the-weak-connected-component-in-the-directed-graph/
解答
这道题如果是无向图的话,我们可以用宽度优先搜索直接扫一遍就可以。但是如果是有向图的话,就不能用宽度优先搜索了。因为边是有向的。 那么怎么才能更好的解决这个问题呢?
那么就只有并查集了。 最开始可以认为图中每个点都是自成一个集合。然后一次遍历每一条边,如果这条边所连的两个点在不同的集合中,那么就用并查集把这两个集合中所有的元素合并起来。 然后最后扫描完整个边后,统计有多少个集合,那么最后就是弱联通分量的数目。
接雨水II
题目
给出 n m 个非负整数,代表一张X轴上每个区域为 1 1 的 2d 海拔图, 计算这个海拔图最多能接住多少(面积)雨水。
解答
由于水是往低处流的, 所以对于这一类trapping water 问题,我们只用从最外层开始往内接雨水就可以。
首先对矩阵外层需要找到最小的柱子,那么就想到用堆,每次堆帮助我们在外层的所有柱子里面找到最小的那根表示可以接的雨水的高度至少是多少,然后进行BSF遍历,如果值相等,继续往下走,如果遇到比当前值小的,或者边境,说明该水流会流出去(遇到这种情况对遍历的数据置为-1)说明往后连通该区域的水都会流出去,如果BFS一遍发现没有到边界和遇到比起小的点,则将遍历过的点的值设为遇到的最小的点,并更新水的流量,继续进行遍历。直至所有点都为-1为止,输出结果
搜索区间
题目
给定一个包含 n 个整数的排序数组,找出给定目标值 target 的起始和结束位置。
如果目标值不在数组中,则返回[-1, -1]
在线测试本题
http://www.lintcode.com/zh-cn/problem/search-for-a-range/
解答
这题考察的是二分查找的特殊情况
二分查找时特殊处理target = A[mid]的情况
1、对搜索left:如果target = A[mid]则继续向左找,否则向右找。直到搜索结束,left = start
2、对搜索right:如果target = A[mid]则继续向右找,否则向左找。直到搜索结束,right = end
3、最后判断如果A[left], A[right] != target,则表明target不存在于数组中, left = right = -1
寻找缺失的数
题目
给出一个包含 0 .. N 中 N 个数的序列,找出0 .. N 中没有出现在序列中的那个数。
在线测试本题
http://www.lintcode.com/zh-cn/problem/find-the-missing-number/
解题报告
这道题类似桶排序问题,如果不能用额外的空间的话,那么其实只需要从0开始遍历到n-1,每次当A[i]!= i的时候,将A[i]与A[A[i]]交换,大于边界的话,丢掉就可以了,直到无法交换位置。 如果有发现 A[i]始终不等于A[A[i]]。那么i就是first missing number
寻找丢失的数
题目
给出一个包含 0 .. N 中 N 个数的序列,找出0 .. N 中没有出现在序列中的那个数。
在线测试本题
http://www.lintcode.com/zh-cn/problem/find-the-missing-number/
解题报告
这道题类似桶排序问题,如果不能用额外的空间的话,那么其实只需要从0开始遍历到n-1,每次当A[i]!= i的时候,将A[i]与A[A[i]]交换,大于边界的话,丢掉就可以了,直到无法交换位置。 如果有发现 A[i]始终不等于A[A[i]]。那么i就是first missing number
寻找旋转排序数组中的最小值
题目
假设一个旋转排序的数组其起始位置是未知的(比如0 1 1 2 4 5 6 7 可能变成是4 4 4 4 4 5 6 7 0 1 2)。
你需要找到其中最小的元素。你可以假设数组中不存在重复的元素。
解答
这道题可以用类似二分方法的形式。
a. A[mid] < A[end]:A[mid : end] sorted => min不在A[mid+1 : end]中
搜索A[start : mid]
b. A[mid] > A[end]:A[start : mid] sorted且又因为该情况下A[end]
搜索A[mid+1 : end]
在线测试本题
http://www.lintcode.com/zh-cn/problem/find-minimum-in-rotated-sorted-array/
搜索旋转排序数组II
题目
假设一个旋转排序的数组其起始位置是未知的(比如0 1 1 2 4 5 6 7 可能变成是4 4 4 4 4 5 6 7 0 1 2)。
你需要找到其中最小的元素。存在重复的元素。
在线测试本题
http://www.lintcode.com/zh-cn/problem/find-minimum-in-rotated-sorted-array-ii/
解答
这道题这道题和上一道题的区别是,数组中可能有相同的数。那么,分下列几种情况, 可以证明,二分方法不再work,比如n个数除了一个数字是3,其他全部是2, 这样就没法确定二分是往左还是往右,于是可以知道这道题的时间复杂度最好就是O(n),既然是O(n) 那么为啥不直接 for循环扫一遍找到答案呢?
尾部的零
题目
设计一个算法,计算出n阶乘中尾部零的个数
在线测试本题
http://www.lintcode.com/zh-cn/problem/trailing-zeros/
解答
方法一
首先求出n!,然后计算末尾0的个数。
方法二
考虑n!的质数因子。后缀0总是由质因子2和质因子5相乘得来的。如果我们可以计数2和5的个数,问题就解决了
比如: n = 5: 5!的质因子中 包含一个5和三个2。因而后缀0的个数是1。
寻找单身狗
题目
给出2 * n + 1 个的数字,除其中一个数字之外其他每个数字均出现两次,找到这个数字。
在线测试本题
http://www.lintcode.com/zh-cn/problem/single-number/
答案
这道题直接就可以利用了异或位运算的一个性质,这个性质是数a与自身异或的结果为0。
所以我们的解法是遍历数组中的每一个元素,并将其进行异或。,所以最终的异或结果将仅仅包含只出现一次的那个数,那个数就是我们的答案。
再寻找单身猫
题目
给出3*n + 1 个的数字,除其中一个数字之外其他每个数字均出现三次,找到这个数字。
在线测试本题
www.lintcode.com
http://www.lintcode.com/zh-cn/problem/single-number-ii/
解答
这道题可以把所有的数看成是的位表示形式, 那么对于哪些出现了三次的数字,如果他们的那些数字如果第i bit位为1,那么我们加3次,再模除三,那么第i位就成为0; 如果第i bit 位位0,那么我们加3次,再模除三,那么第i位也会成为0。 第i位唯一不为1的就是多出来的那个数。
所以我们的做法就是把所有的数字按照bit位,每一位加起来模除3,然后最后剩下的就是我们要找的数,然后再把它按照每一位复原成为十进制的数。
实现Trie树
题目
实现一颗字典查找树Trie
在线测试本题
http://www.lintcode.com/en/problem/implement-trie/
解答
trie树又名,前缀树,因为是把字典按照前缀来建树建成就是trie 树。Trie 树可以用作字典的压缩存储,可以节省空间,但是和hash相比不节省时间。
这题实质是实现一颗多叉树的插入和查找操作(如果只有小写字母trie树就是26叉书)。
每个节点上面保存了26个指针。 插入的时候,从上到下一边深度优先遍历的时候一边把字符串每个字符一个一个插入trie树每一层。如果一层插入的时候没有该节点 ,那么就相应的初始化。这里有一个特殊的地方就是每个字符串结尾的地方要做一下标记表示改节点是字符串的结尾。
查询操作,相应的也是从根节点从上到下依次一边深度优先搜索一边插入,每一个字符都可以从上到下对应前缀树的每一层,如果找不到就返回,如果找到最后一个节点是特殊标记过的,就说明这个字符串在trie树对应的字典里面。
报数
题目
报数指的是,按照其中的整数的顺序进行报数,然后得到下一个数。如下所示:
1, 11, 21, 1211, 111221, …
1 读作 “one 1” -> 11.
11 读作 “two 1s” -> 21.
21 读作 “one 2, then one 1” -> 1211.
给定一个整数 n, 返回 第 n 个顺序。
在线测试本题
http://www.lintcode.com/zh-cn/problem/count-and-say/
解答思路
这道题基本上就是一个模拟的题目,不断遍历字符串,每一次遍历一个新的字符的时候看后面有多少字符是跟前面的一样的。 这样相当于按照相同的字符一层一层的遍历而不是一个字符一个字符的遍历。
空格替换
题目
设计一种方法,将一个字符串中的所有空格替换成 %20 。你可以假设该字符串有足够的空间来加入新的字符,且你得到的是“真实的”字符长度。
样例
对于字符串”Mr John Smith”, 长度为 13
替换空格之后的结果为”Mr%20John%20Smith”
在线测试本题
http://www.lintcode.com/zh-cn/problem/space-replacement/
解答
这道题非常直观,也基本是模拟题目, 比较好的一个处理方式是先扫一遍知道有多少个空格,然后算出总过的新数组需要的 长度,从string的末尾倒着遍历。这样遇到空格的时候可以替换成为%20这样就好处理很多啦。
Two Sum II
题目
给一个数组,还有一个元素target,找出数组里面有多少对元素之和大于target.
在线测试本题
http://www.lintcode.com/zh-cn/problem/two-sum-ii/
解答
这道题非常类似two sum ,。我们可以用类似于两个指针的方式, 来做这道题目。
先把数组排序了后, 然后两个指针一个指向头head,一个指向尾巴tail,然后判定a。如果A[head]+A[tail]> target 那么所有head右边的元素和tail 的组合的和都是大于target的,所以我们更新答案,tail减一继续扫b。如果A[head]+A[tail]<=target,那么tail左边的所有的元素和head的组合的和都是小于等于target的,所以我们不用考虑了, head加一继续扫描。这样到最后,head和tail相遇,停止整个扫描就阔以得到答案。
三角形计数
题目
给一个数组,还有一个元素target,找出数组里面有多少对元素之和大于target.
在线测试本题
http://www.lintcode.com/en/problem/triangle-count/
解答
这道题跟2 sum II 非常类似。 因为我们要找的是三个元素A[x],A[y],A[z]满足,
A[x]+A[y] > A[z]
A[x]+A[z] > A[y]
A[y]+A[z] > A[x]
就可以了。 那么怎么样实现呢?朴素的解放是o(n^3)的, 那么怎么样优化时间复杂度呢?我们可以先把数组排序, 然后如果默认x< y < z的话,可以推出,A[x] < A[y] < A[z] 所以上面条件里面2,3 一定成立。 那么接下来我们要做的就是对于每一个z我们要找x,y 使得A[x]+A[y]>A[z] , 其实这样我们可以枚举所有的z, 然后固定z了后, 不就是找有多少个x和y的组合,使得他们的和大于 A[z] 这就是2 sum II 的问题, 我们可以借鉴2 sum II的方式来做, 最后的时间复杂度就是O(n^2)的时间复杂度。
石子合并
题目
在一个圆形操场的四周摆放着n堆石子(n<= 100),现要将石子有次序地合并成一堆。规定每次只能选取相邻的两堆合并成新的一堆,并将新的一堆的石子数,记为该次合并的得分。
在线测试本题
http://www.lintcode.com/zh-cn/problem/stone-game/
解答
这道题是区间DP里面的经典考题。
怎么来构思这样的问题呢?
首先我们要求把一条直线上的所有的石子合并,这个问题比较大,那么怎么拆分呢?我们可以从小的入手,从最开始只有一个是石子的情况。举一个例子:(3 4 6 5 4 2)来说:
第一阶段只有一个石子:
s[1,1]=0,s[2,2]=0,s[3,3]=0,s[4,4]=0,s[5,5]=0,s[6,6]=0,
因为一开始还没有合并,所以这些值应该全部为0。
第二阶段有两个石子的时候:
两两合并过程如下,其中sum(i,j)表示从i开始数j个数的和
s[1,2]=s[1,1]+s[2,2]+sum(1,2)
s[2,3]=s[2,2]+s[3,3]+sum(2,3)
s[3,4]=s[3,3]+s[4,4]+sum(3,4)
s[4,5]=s[4,4]+s[5,5]+sum(4,5)
s[5,6]=s[5,5]+s[6,6]+sum(5,6)
由于这两部的分析,那么我们的其他状态f[i][j]就清晰了是dp[i][j] = min(dp[i][k]+dp[k+1][j]+sum[i,j]。
有了上面的状态分析,下面我们直接给出这题动态规划的四要素:
State: dp[i][j] 表示把第i到第j个石子合并到一起的最小花费
Function:
预处理sum[i,j]
dp[i][j] = min(dp[i][k]+dp[k+1][j]+sum[i,j]) 对于所有k属于{i,j}
Intialize:
dp[i][i] = 0 for each i.
Answer:
dp[0][n]
二叉树路径求和
题目
给定一个二叉树,找出所有路径中各节点相加总和等于给定 目标值 的路径。
一个有效的路径,指的是从根节点到叶节点的路径。
在线测试本题
http://www.lintcode.com/zh-cn/problem/binary-tree-path-sum/
解答
这道题的可以用递归回溯的方式, 一边可以用递归遍历深度优先整棵树,传入从根节点沿着递归搜索一直搜到当前节点路径所有元素的和和搜索过路径上面的节点。 一旦找到一个叶子节点判断当前path sum 是不是等于target,如果等于那么就找到一个合法的路径。 存入到答案里面。
相亲数
题目
一对整数是相亲数是说他们各自的所有有效因子(除了自己以外的因子)之和等于另外一个数。比如(220, 284)就是一对相亲数。因为:
220的所有因子:1+2+4+5+10+11+20+22+44+55+110 = 284
284的所有因子:1+2+4+71+142 = 220
给出整数k,求1~k之间的所有相亲数对。
在线测试本题
http://www.lintcode.com/zh-cn/problem/amicable-pair/
解答
这是一道模拟题,要做的就是按照题意,首先遍历一遍k内的所有元素。 如果当前遍历到的第i元素,检查第i个元素的所有因子和sum, 然后再求一遍这个sum值所有因子的和看是否等于i,如果等于那么i和sum就是amicable pair 输出这个元素。
姓名去重
题目
给出一串名字字符串,把所有名字转成小写了后,去掉重复的名字字符串,然后输出。
在线测试本题
http://www.lintcode.com/zh-cn/problem/name-deduplication/
解答
这道题分两步来解答。 第一步,把所有字符串转换成为小写字符串, 第二步,扫面一遍每个变成小写后的字符串,一边扫描一边把已经放入Hash表里面以便判断有么有扫过重复的元素,每次扫到下一个字符串之前,检查一下hash表里面之前扫过的元素是否出现过就可以知道有么有重复的元素。
这道题主要主要在于两个知识要点:1,大小写转换。 2,hash表使用。
public String toLowerCase()
public String toUpperCase()
矩阵归零
题目
给定一个m×n矩阵,如果一个元素是0,则将其所在行和列全部元素变成0。
需要在原地完成。
在线测试本题
http://www.lintcode.com/zh-cn/problem/set-matrix-zeroes/
解答
这道题要我们把有零的行或者列全部变成0, 所以我们的算法是分两步,第一步,找到有零位置, 知道是哪一行,哪一列是有零的行或者列,并且存储在数组里面。 第二步,扫描一遍每一行,如果这一行之前知道是有零的行,就把这一行所有元素变为0。 同理扫描每一列,知道是有零的列,就把这一列所有元素变为0.
回文数
题目
判断一个正整数是不是回文数。
回文数的定义是,将这个数反转之后,得到的数仍然是同一个数。
在线测试本题
http://www.lintcode.com/zh-cn/problem/palindrome-number/
解答
这道题是判断数字是不是回文数, 其实就是把一个数字翻转了后,和原来的数比较是否相等。这道题的难点是数字怎么翻转。 有的同学可能认为可以把数字转换成为字符串来翻转,其实没有必要那么复杂,只用数字处理,每次模10得到每一位的数字,然后把数字翻转。
二叉树的所有路径
题目
给一棵二叉树,找出从根节点到叶子节点的所有路径。
在线测试本题
http://www.lintcode.com/zh-cn/problem/binary-tree-paths/
解答
这道题要打印根节点到叶子节点的全部路径, 曾经我们有总结过,如果是输出全部路径的题目,那一定会想到深度搜索的方式。接下来怎么打印呢?只需要在深度优先搜索的每一层的时候用Arraylist保存从根节点到当前节点的所有路径上面的点。然后判断如果是叶子节点,那么当前是一个可行解,保存在最后要返回的答案里面。
数飞机
题目
给出飞机的起飞和降落时间的列表,用 interval 序列表示. 请计算出天上同时最多有多少架飞机?
在线测试本题
http://www.lintcode.com/en/problem/number-of-airplanes-in-the-sky/
解答
这道题是扫描线的基础题目。 首先题目虽然给我们很多区间,很多同学喜欢把区间弄来排序,比如按照区间开始,或者区间结尾排序。 这样做就是题目麻烦很多。比较好的方式是,把每个区间拆开成为两个时间的点,一个是开时间点,一个是闭时间点,每个点当然要知道他的具体时间是多少。然后把所有的点按照时间排序。 然后模拟一条扫描线,从最开始的时间一直扫描到最终的时间,扫描的过程当中,维护一个值count记录当前在天上飞机数目,如果遇到一个开始点,那么说明有一架飞机起飞count+1,如果遇到闭时间点,说明有一架飞机下落count-1。 然后看count最大的时候,就是天上飞机最多的时候。
硬币排成线
有 n 个硬币排成一条线。两个参赛者轮流从右边依次拿走 1 或 2 个硬币,直到没有硬币为止。拿到最后一枚硬币的人获胜。
请判定 第一个玩家 是输还是赢?
这道题是属于博弈类的问题,首先先介绍一下博弈类问题的一些概念。 两个参赛者,先玩游戏的我们叫做先手,后玩游戏的叫做后手。 然后这种博弈问题有两个解法,一种是贪心的解法,一种是dp的解法, 这里我们只介绍dp的解法 。
一般这种问题直接定义dp状态比较困难,所以可以先分析题目,从大问题向小问题思考。 也就是dp里面的记忆化搜索的思考方式。
我们先从先手考虑,如果是先手在还是n个硬币的时候, 那么先手可以有两个策略,取一个硬币或者是两个硬币。那么现在硬币还是n-1或者n-2个,剩下如果n-1个硬币,后手也可以有两个选择,取一个硬币或者两个,那么还剩n-2或者n-3个。
如果剩下n-2个硬币给后手,那么还剩n-3或者n-4个。
那么这样我们就可以其实可以用剩余硬币的数目作为状态定义。另外博弈类问题为了方便其实尝尝只考虑定义先手的状态。 把后手的状态放入方程中。
所以我们看看这道题动态规划的四要素:
State: f[x] 现在还剩x个硬币,现在先手取硬币的人最后输赢状况
Function:
f[n] = (f[n-2]&& f[n-3]) || (f[n-3]&&f[n-4] )
f[n-2]&& f[n-3]表示后手在选手取了一个硬币还剩n-1个硬币的时候,要选一种方案让先手输,如果是先手要赢这里需要取交。
f[n-3]&& f[n-4]表示后手在选手取了一个硬币还剩n-1个硬币的时候,要选一种方案让先手输,如果是先手要赢这里需要取交。
在还剩n个硬币的时候,先手可以自己选择取一个或者两个硬币所以这里取并。(f[n-2]&& f[n-3]) || (f[n-3]&&f[n-4] )
Intialize:
f[1] = true
f[2] = true
f[3] = false
f[4] = true
Answer: f[n]